.svg)


The Working Memory Problem
If you've tried to use an LLM for anything beyond generating a utility function (understanding a module's business logic, tracing a data flow across files, figuring out why a particular function exists…) you've felt the constraint.
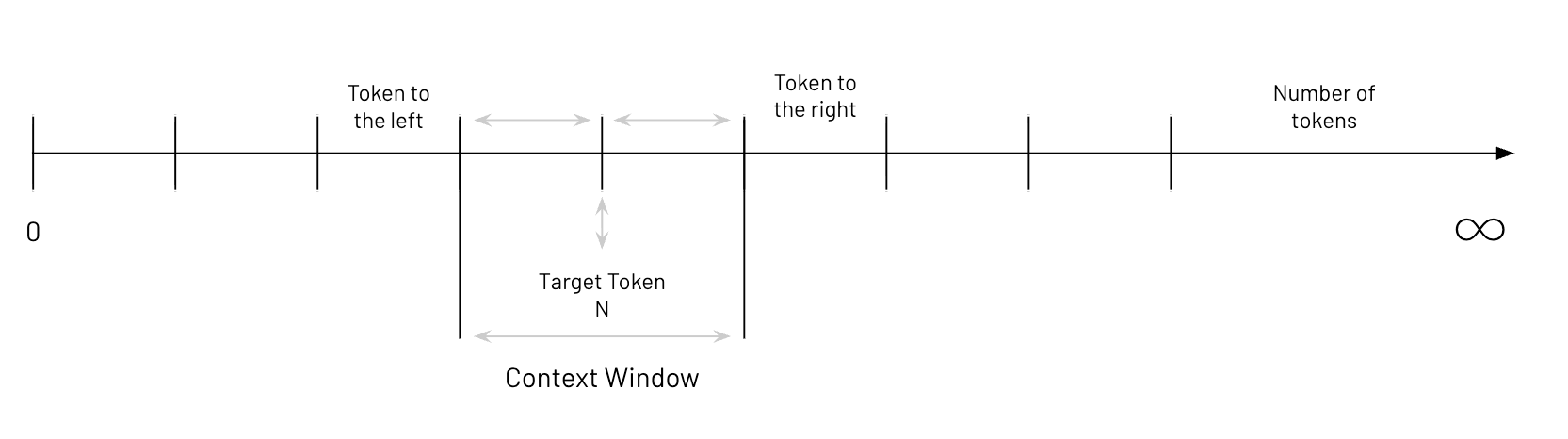
A context window is the working memory of a large language model. It's the lens through which the model sees everything: your prompt, the conversation history, any code or documents you've fed it with. The model doesn't have persistent memory. It has a sliding window of tokens, and everything it knows about your problem has to fit inside that window.
Three things determine what happens inside that window:
- The focal point — the model is always attending to specific tokens and surrounding text, deciding what matters.
- The contextual relationships — the model interprets connections between tokens to build an internal representation of meaning, not just pattern-matching strings.
- The window size — the hard ceiling on how much data the model can hold in its working set at any given moment.
For a developer pasting in a few files to ask about business logic, these constraints become real fast. You hit token limits. Or worse, the model seems like it has room, but the output is wrong because critical context got pushed out of the window or diluted by everything else in there.
Why Context Windows Matter for Engineering Work
The quality of an LLM's output on engineering tasks is directly tied to the context it can access. This plays out in three ways that matter for anyone working with real codebases.
Code understanding requires surrounding context. When an LLM is parsing legacy code, it needs more than the function signature. It needs the imports, the calling code, the data structures being passed around, the copybooks being referenced. Without that surrounding context, the model is guessing. And on a mainframe modernization, guessing is how you introduce regressions that surface during month-end processing, the kind where your general ledger is suddenly off by six figures.
Pattern conformance depends on visible patterns. LLMs adapt their outputs based on patterns observed in the context window. Feed the model well-structured context (naming conventions, architectural patterns, error handling standards, business rules) and it learns to conform. But only if that context fits in the window. Lose it, and the model generates code that looks right syntactically but violates every convention your team has established.
Coherent generation requires architectural visibility. When an LLM generates code that integrates with an existing codebase, coherence isn't optional. The output must match the style, error handling patterns, architectural decisions, and even commenting conventions of what's already there. That requires the model to see those patterns, which means context.
The context window isn't just a technical spec on a model card. It's the bottleneck that determines whether AI-assisted engineering produces usable code or generates plausible-looking output that passes a review but fails in production.
The Obvious (Wrong) Answer
The first thing every engineer asks: why not just make the context window bigger?
If the problem is fitting enough context, expand the window. A million tokens. Ten million. Problem solved. Not quite.
Anyone who's worked with the larger context models has probably noticed that throwing everything in doesn't magically improve output. Sometimes it actually makes things demonstrably worse. More hallucinations, not fewer. Confident-sounding but incorrect answers. The model blending code from different modules as if they were the same thing.
There are specific, well-documented reasons why.
The Paradox: Four Reasons Bigger Breaks Down
Information Overload
This one's intuitive and it happens to people too. Dump hundreds of thousands of tokens of COBOL into a model and ask it to find the business rule for calculating late fees. The model has to sift through JCL, copybooks, dead code, and commented-out sections from decades ago to find the relevant logic. More noise means more opportunities to latch onto the wrong thing.
From a practical standpoint, larger contexts mean quadratically more compute in the attention mechanism, slower responses, and higher cost. On a large project processing thousands of programs, that cost compounds fast.
Lost in the Middle
This is well-documented in the research literature. LLMs exhibit what's called the "lost in the middle" problem, where they disproportionately attend to information at the beginning and end of the context window and pay significantly less attention to what's in the middle. It's an artifact of how attention mechanisms are trained.
If your critical business logic lands in the middle third of a large context dump (and statistically, a third of it will) the model might effectively ignore it. The tokens are present. The information is there. But the attention weights are too diluted for the model to actually use it.
Poor Signal-to-Noise Ratio
When the window is packed full, the model struggles to differentiate what's important from what's noise. You get redundancy — the model restating the same concept in different ways. Contradictions — code that conflicts with patterns established elsewhere in the context. And bias amplification — if there's more boilerplate than business logic in the context, the model generates boilerplate-flavored answers even when you're asking about specific business rules.
Long-Range Dependency Decay
This is the killer for legacy modernization specifically. Going back to the large COBOL application example, a business rule might span multiple paragraphs, reference a copybook defined in a completely different member, depend on a working storage variable set three PERFORM THRU calls earlier, and behave differently based on a condition flag initialized in the JCL.
These long-range dependencies (cause and effect separated by thousands of lines of code) are exactly what LLMs struggle with in large contexts. The attention mechanism degrades over distance. Concepts far apart in the token stream become weakly connected in the model's internal representation.
The paradox is real: you need more context to understand complex systems, but more context degrades the model's ability to reason about what's in the window. You cannot brute-force your way to understanding a million-line codebase by dumping it all into a prompt.
Putting Numbers to the Problem
Let's make this concrete with real numbers instead of abstractions.
The current landscape of context window sizes tells the story. The largest commercially available context windows today top out around one million tokens. Most production models sit between 128K and 200K tokens. Open-source models commonly offer 8K to 16K.
Now consider a real enterprise codebase. A million lines of code — and many mainframe shops that estimate half a million actually have two million once you count copybooks, JCL, utility programs, and batch processing logic. A conservative million lines at roughly 50 characters per line gives 50 million characters. At approximately 4 characters per token, that's around 12.5 million tokens.
The largest context window on the market fits less than eight percent of a modest legacy codebase. Not even close.
And remember, even if it all fit, the paradox means you wouldn't want to send it all. Quality degrades well before you hit the ceiling.
Layer on the business reality. Research from Sonar across more than 200 projects found that technical debt costs approximately $306,000 per year per million lines of code. That's the maintenance burden: bugs from code nobody fully understands, fragility in systems nobody wants to touch, developer hours spent reverse-engineering undocumented logic.
The Solution: Intelligent Decomposition, Not Bigger Windows
What if, instead of trying to cram a whole codebase into a context window, you intelligently decomposed it first? Not randomly, not chunking by line count or by file, but following the natural taxonomy of the code itself. Respecting the boundaries the original developers built into the system.
This is the approach CoreStory takes with its code intelligence platform, and it works in two phases.
Phase one: Progressive Decomposition. The full codebase breaks down along its natural architectural boundaries. The full system decomposes into modules. Modules decompose into classes or programs. Programs decompose into functions, paragraphs, and procedures. This isn't arbitrary chunking — it follows the structure the original developers created, because that structure encodes how business logic is organized.
The craft is in getting the boundaries right. You don't chunk in the middle of a function. The decomposition has to be semantically aware. It has to understand what constitutes a meaningful unit of code. Get the chunking wrong and you get garbage out. Get it right and you get specifications that reflect reality.
At each level of decomposition, enterprise context gets applied — naming conventions, architectural patterns, coding standards, the things senior engineers know intuitively but that aren't written down anywhere. The output conforms to your world, not to generic training data.
Phase two: Progressive Recomposition. Once each piece is analyzed with properly scoped context (context that fits in the window and gives the model everything it needs) the understanding recomposes back up the chain. Function-level analysis composes into class-level specs. Class specs compose into module-level documentation. Module specs compose into full-system requirements.

What emerges is structured code intelligence: not raw code, but persistent, queryable specifications that an LLM can reason about effectively. When you send context to a model, you're sending well-structured, properly scoped specs that fit within the window and give the model exactly what it needs.
Real life application of this approach showed that Claude Code paired with CoreStory used 73% fewer input tokens.
What This Unlocks in Practice
The technology only matters if it delivers real value. Here's what becomes possible when you solve the context problem.
Actual business requirements from code, not restated syntax. Not auto-generated comments that parrot the code in English, but real business requirements extracted from code behavior. Product requirement documents that describe what the system does in business terms. For many organizations, this alone justifies the effort: you finally get a source of truth for what the system actually does, rather than what someone wrote in a design document years ago.
Feature-to-code mapping for modernization and maintenance planning. Once requirements are mapped to code modules, you can plan with data instead of intuition. Which modules carry the most business risk? Which have the most technical debt? Which are the best candidates for modernization first because they're self-contained? You have a traceable map from business capability to code implementation.
Persistent context for all future AI-assisted development. The structured intelligence becomes seed data for every subsequent AI interaction. Every prompt, code generation task, and code review starts with accurate context about your enterprise's patterns, conventions, and architecture. You stop starting from zero every time you open a new chat session. This is what context engineering looks like at enterprise scale: persistent understanding that compounds over time rather than evaporating with each session.
Compressed engineer ramp time. Consider how long it takes a new developer to become productive on an existing system today. With structured, searchable specs tied directly to the running code, that ramp compresses dramatically. And existing engineers spend less time spelunking through code before they can change it.
This comes up consistently in customer conversations: the problem isn't writing new code, it's understanding what the old code actually does before you can safely touch anything.
Ready to Solve the Context Problem?
If you're sitting on a legacy system that needs modernization or a critical application that needs to be maintained, but you haven't found an approach that handles the scale and complexity of your codebase, the context window paradox is likely the root cause. CoreStory's code intelligence platform was built specifically to solve it.
Talk to an expert about running a focused assessment on your codebase, or try CoreStory free to see the platform in action.
FAQ
What exactly is the "lost in the middle" problem?
It's a well-documented behavior in LLMs where the model pays significantly more attention to information at the beginning and end of its context window than to information in the middle. Even when tokens are present in the window, the model may not effectively use them if they fall in the middle portion. This means critical business logic can be functionally invisible to the model even when it's technically within the context.
Can't I just use RAG (retrieval-augmented generation) to solve this?
RAG helps surface relevant chunks, but it doesn't solve the fundamental problem. RAG retrieves text fragments based on semantic similarity, which works well for documentation lookup but poorly for understanding code structure, cross-file dependencies, and business logic that spans multiple modules. You still need those retrieved chunks to fit meaningfully in the context window, and you still need the model to reason about their relationships correctly. Progressive decomposition and structured code intelligence give the model properly scoped, architecturally coherent context — not disconnected fragments.
How is CoreStory's approach different from just splitting code into smaller files?
Splitting code into arbitrary chunks (by file, by line count, by function) ignores the semantic structure of the codebase. CoreStory's progressive decomposition follows the natural architectural boundaries of the code, preserving the relationships and dependencies that make each unit of analysis meaningful. The recomposition phase then rebuilds understanding across those boundaries so nothing falls through the cracks.
What programming languages does this work with?
CoreStory supports a large variety of programming languages, from legacy systems like COBOL and Natural/ADABAS to modern stacks in Java, C#, Python, and more. The platform is designed for enterprise environments where multiple languages and frameworks coexist in the same system.
What size codebases can CoreStory handle?
The platform is built for enterprise scale. The progressive decomposition approach means codebase size isn't a limiting factor the way it is with raw context window approaches. Whether your system is hundreds of thousands or millions of lines, the analysis follows the same architectural decomposition methodology.