.svg)


The Reproducibility Problem
Imagine presenting a modernization plan to your board. The budget is based on a code analysis that estimated 847 business rules in your legacy system. The CTO asks: "Run it again. Let's verify." The second run finds 912 business rules. A third finds 783. Which number do you put in the budget?
This isn't a hypothetical. It's what happens when enterprise teams use non-deterministic AI tools for code analysis. Large language models generate text based on statistical distributions. Every generation involves randomness (temperature parameters, sampling strategies, token selection probabilities) that could make each output slightly different from the last. For creative writing, this is a feature. For enterprise code analysis, it's a fundamental problem.
The question came up directly in customer conversations with multiple enterprise accounts: "If I type the same question twice, will I get the same answer?" The fact that engineering leaders feel the need to ask this question tells you everything about the current state of AI-based code analysis.
Structural Analysis vs. Probabilistic Generation
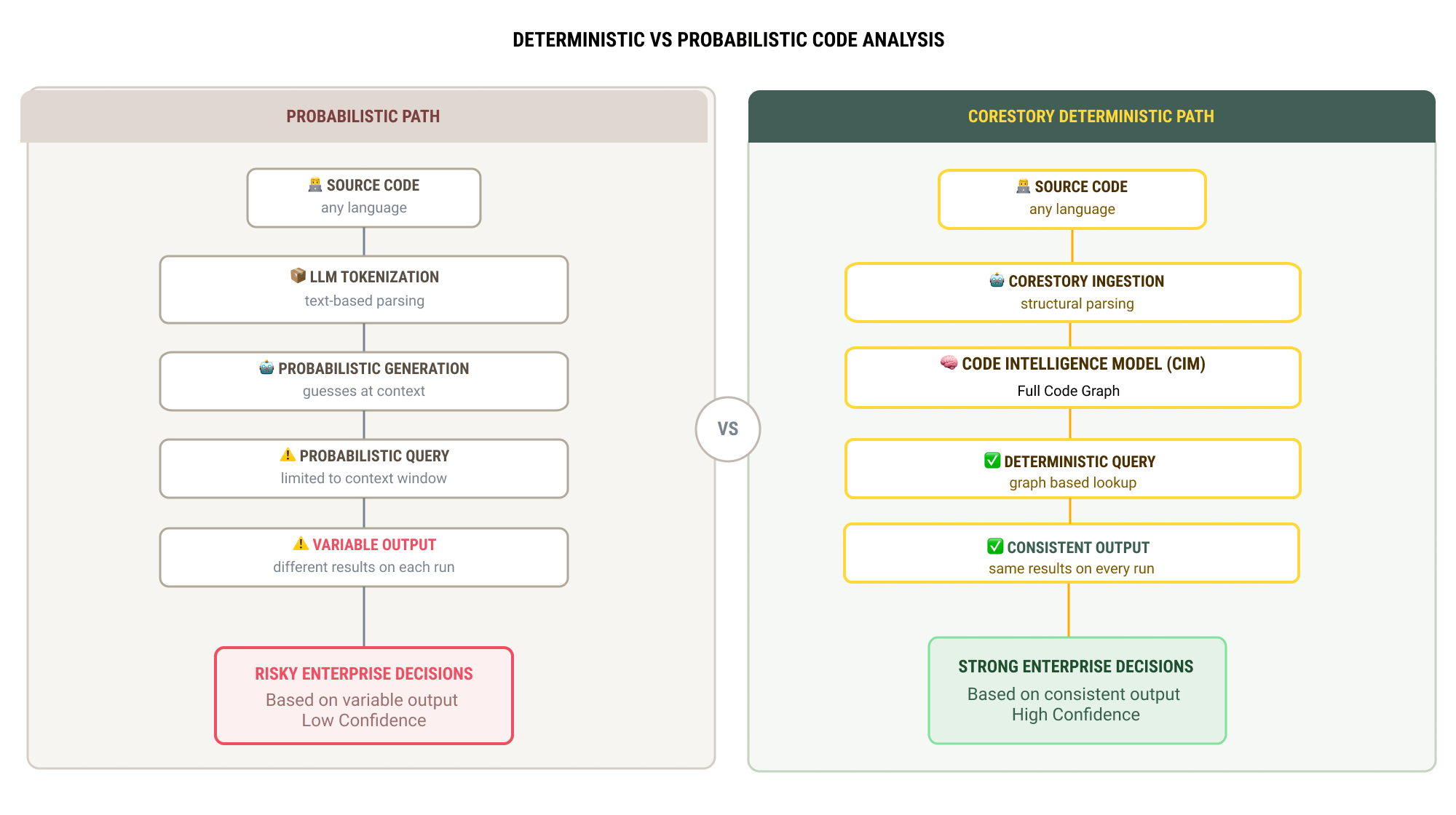
The distinction between deterministic and probabilistic analysis is architectural, not parametric. It's not about setting the AI model's temperature to zero (which reduces but doesn't eliminate variation in most LLM architectures). It's about the fundamental approach to understanding code.
How probabilistic tools work
General-purpose AI tools process code as text. They read source files, tokenize them, and generate analysis through sequential token prediction. Each token is selected from a probability distribution, which means the output is inherently variable. Even with low-temperature settings, factors like context windows, prompt structure, and model state can produce different results across runs.
This approach works well for many tasks: code explanation, suggestion generation, and conversational queries about code behavior. But it produces analysis that is inherently non-reproducible at the precision level enterprise decisions require.
How CoreStory's Code Intelligence Model works
CoreStory builds a structural representation of your codebase, a graph that maps entities (functions, classes, stored procedures, configuration entries) and their relationships (calls, dependencies, data flows, business rule chains). This Code Intelligence Model (CIM) is deterministic by construction: the same codebase produces the same graph, which produces the same analysis, every time.
When you query the CIM for business rules in a specific module, the answer is derived from the graph structure, not generated from a probability distribution or just a keyword search. The business rules are either in the graph or they aren't. The dependencies either exist or they don't. There's no sampling involved.
What Determinism Means in Practice
Deterministic analysis isn't just a technical property — it changes how enterprise teams can use the results.
Baseline comparisons become meaningful
When analysis is deterministic, you can run CoreStory on your codebase today, make changes over the next quarter, and run it again. The differences between the two outputs represent actual changes in your system — not noise from the analysis tool. This makes CoreStory usable as a change detection mechanism: what business rules changed between releases? What new dependencies were introduced? What previously-documented behaviors were removed?
With probabilistic tools, this comparison is unreliable. You can't tell whether a difference in the output reflects a real change in the code or is the result of variability in the analysis pipeline.
Audit trails require reproducibility
In regulated industries like financial services, insurance, government, or healthcare, audit requirements demand that analysis results be reproducible. If a regulator asks how you determined that a specific business rule exists in your system, you need to be able to re-run the analysis and get the same answer.
This requirement surfaced consistently in customer conversations with insurance companies, government agencies, and financial services firms. The auditability of analysis results isn't a nice-to-have, it's a compliance requirement that probabilistic tools fundamentally cannot satisfy.
Team coordination depends on a shared truth
When multiple teams are working on a project (architects designing the target state, developers implementing changes, testers validating behavior) they all need to be working from the same understanding of the current system. If the analysis tool produces different results for different teams (or for the same team on different days), coordination breaks down.
Deterministic analysis means there's one version of the truth. The architecture team's understanding of the system is the same as the development team's understanding is the same as the testing team's understanding. This sounds obvious, but it's impossible to guarantee with non-deterministic tools.
When and Why Outputs Might Differ
Honest transparency requires acknowledging that CoreStory's outputs can change between analysis runs, but only for documented, traceable reasons:
- Code changes. If the source code changes between runs, the analysis will reflect those changes. This is expected and the designed behavior since the CIM represents the current state of the code.
- Expanded input scope. If you add stored procedures, configuration files, or additional repositories to the analysis that weren't included in the previous run, the output will reflect the additional context. More complete input produces more complete intelligence.
- Model updates. When CoreStory updates its analysis models (for example, to improve accuracy for a specific language or framework), the output may change, but will always be semantically similar to the ground truth as represented in the CIM.
What will not cause output variation: running the same analysis on the same codebase with the same model version. This is the reproducibility guarantee that enterprise teams need.
The Enterprise Decision Chain
The practical impact of deterministic analysis flows through the entire enterprise decision chain:
Planning: Roadmaps based on deterministic analysis can be budgeted, scheduled, and staffed with confidence. The scope won't shift because the analysis tool produced different results on the next run.
Execution: Development teams can code against specifications that won't change unless the underlying code changes. Test teams can validate against a stable baseline.
Governance: Compliance teams can audit analysis results and reproduce them independently. Change advisory boards can review the impact of proposed changes against a reliable system model. Risk assessments are based on stable data.
Continuous improvement: As the system evolves, successive deterministic analyses create a reliable history of how the system has changed over time — a "context graph" or a versioned record of business logic evolution that has significant value for institutional knowledge.
Need reproducible code intelligence for your modernization project? Talk to an expert about how CoreStory delivers deterministic analysis at enterprise scale.
FAQ
Can't I just set the LLM temperature to zero for deterministic results?
Setting temperature to zero reduces, but doesn't eliminate, variability in most LLM architectures. Factors like context windows can still produce different outputs. More fundamentally, the analysis is still based on token prediction rather than structural understanding. You get more consistent text, but not necessarily more consistent analysis.
Does deterministic mean the analysis is always correct?
Deterministic means reproducible, not infallible. If the analysis misses a business rule on the first run, it will consistently miss it on subsequent runs, which means the gap is identifiable and fixable. This is preferable to probabilistic tools where errors are intermittent and harder to diagnose.
What about the chat interface, are chat responses deterministic too?
CoreStory's chat interface queries the Code Intelligence Model, so responses about code structure, business rules, and dependencies are grounded in the deterministic CIM. However, the natural language generation layer that formats responses may vary slightly in phrasing across identical queries. The underlying analysis (the facts, numbers, and relationships) remains consistent.