.svg)


What Counts as a Business Rule in COBOL
Before choosing a tool, you need to define what you’re extracting. In modern languages, business rules are often isolated in service layers or rule engines. In COBOL, they’re woven through the code. A single business rule in a COBOL system might involve:
A COMPUTE statement that calculates a premium based on risk factors defined in a copybook shared across 15 programs.
An EVALUATE block that routes processing based on transaction type codes stored in a VSAM file.
A chain of PERFORM statements that validate eligibility by checking conditions across three separate programs, each with its own copybook definitions.
Implicit rules encoded in data definitions like a PIC 9(2) field that constrains a value to 0–99, enforcing a business constraint that exists nowhere in documentation.
The difficulty is that these rules weren’t designed to be extracted. They evolved over decades of maintenance by dozens of developers, many of whom are no longer available to explain their intent. Dead code intermingles with active logic. Copybook definitions are shared across programs in ways that create invisible dependencies. GOTO statements create control flows that resist automated analysis.
This is why generic AI tools fail at COBOL rule extraction. You can’t prompt your way through a system where a single business rule spans files, copybooks, and database calls, with critical context encoded in data type definitions.
In this article we’ll look at three approaches available today, and look at their advantages and shortcomings.
Approach 1: Static Analysis Tools
The established category for COBOL analysis is static analysis and dependency mapping. These tools parse COBOL source code and produce visualizations of program relationships, data flows, and control flows.
IBM Application Discovery and Delivery Intelligence (ADDI)
IBM ADDI is the most widely deployed tool for mainframe application analysis. It’s purpose-built for z/OS environments and provides:
Cross-program dependency mapping: detects relationships between COBOL programs, JCL jobs, DB2 calls, IMS transactions, and datasets.
Change impact analysis: traces forward and backward from any program or variable to identify what breaks if you modify it.
Program call graphs: visual representations of control flow between programs.
DB2 metadata analysis: pulls schemas from all DB2 tables associated with a job.
ADDI excels at answering the dependency question of “what is connected to what”. It’s a critical first step in any modernization project because it prevents teams from making changes that break downstream processes they didn’t know existed.
Where ADDI is limited is in answering the business rule question of “what does the code mean”. ADDI provides a graphical model of COBOL code that shows variable usage, data flows, and program relationships. But translating that structural information into documented business rules requires human interpretation. ADDI shows you the machinery but understanding what the machinery does is still a human task.
IBM’s modernization stack pairs ADDI with watsonx Code Assistant for Z, which uses AI agents to generate natural language explanations of mainframe code. Together they form a pipeline: ADDI provides the structural analysis, watsonx provides AI-assisted explanation. This combined approach is powerful but remains tightly coupled to the IBM ecosystem.
CAST Imaging
CAST Imaging provides architecture-level visualization of legacy applications, including COBOL. It creates interactive maps of software systems that show components, dependencies, data flows, and transaction paths.
CAST’s strength is cross-technology analysis. It can map a system that includes COBOL programs, Java middleware, SQL databases, and web frontends, showing how they all connect. For organizations with heterogeneous technology stacks, this cross-technology view is valuable for modernization planning.
Like ADDI, CAST Imaging is primarily a visualization and analysis tool. It shows you the structure of your system with impressive clarity but doesn’t generate business rule documentation automatically. The business rule extraction work still requires analysts to interpret the visualizations and write specifications.
Other static analysis tools
Micro Focus Enterprise Analyzer (now part of OpenText) provides similar capabilities for COBOL, PL/I, and Natural applications. Fresche Solutions’ X-Analysis Advisor is specifically designed for IBM i environments, extracting rules from RPG and COBOL and writing them in pseudo code. IBM’s Rational Asset Analyzer provides centralized analysis and inventory management for mainframe application portfolios.
Approach 2: LLM-Assisted Extraction
The emergence of large language models trained on programming languages has created a new approach: feeding COBOL paragraphs to an LLM and asking it to summarize the business logic in natural language.
The pipeline typically works paragraph by paragraph: extract a COBOL section, send it to GPT-4, Claude, or a specialized model with a prompt like “explain the business logic in this COBOL code”, and collect the natural language summary. More sophisticated implementations use prompt chaining: first identify variables and data flows, then trace decision logic, then summarize the business rule.
What LLM-assisted extraction does well
Fast iteration: you can process hundreds of COBOL paragraphs in hours rather than weeks.
Natural language output: the summaries are immediately readable by business analysts who don’t know COBOL.
Pattern recognition: LLMs are good at recognizing common COBOL patterns (date calculations, table lookups, record processing) and explaining them clearly.
Where LLM-assisted extraction fails
LLMs hallucinate. This is not a theoretical risk — it’s the primary failure mode for LLM-based COBOL analysis. An LLM that “explains” a COBOL paragraph may confidently describe logic that doesn’t exist, miss critical edge cases encoded in copybook definitions it never saw, or invent variable relationships that are plausible but wrong.
The problem compounds at scale. A single hallucinated business rule in a modernization specification can propagate through the entire project and as a result the new system implements a rule that the old system never enforced, or misses a rule that the old system depended on. In regulated industries (banking, insurance, healthcare), this isn’t just a bug; it’s a compliance violation.
IBM Research’s A-COBREX tool (presented at ICSE 2025) demonstrates the state of the art in automated COBOL business rule identification. Evaluated on 27 programs with ground truth annotations, A-COBREX achieved 74.12% recall and 62.21% precision for fuzzy matching between extracted and actual rules. These numbers reflect the genuine difficulty of the problem: even purpose-built research tools miss roughly a quarter of the rules and include false positives in more than a third of their output.
The LLM-assisted approach works best when paired with strong structural analysis (like ADDI) and mandatory human validation gates. Using an LLM alone to extract business rules from production COBOL is like using autocomplete to write a legal contract: the output looks right, but the stakes are too high for “looks right.”
Approach 3: AI Code Intelligence with Validated Specifications
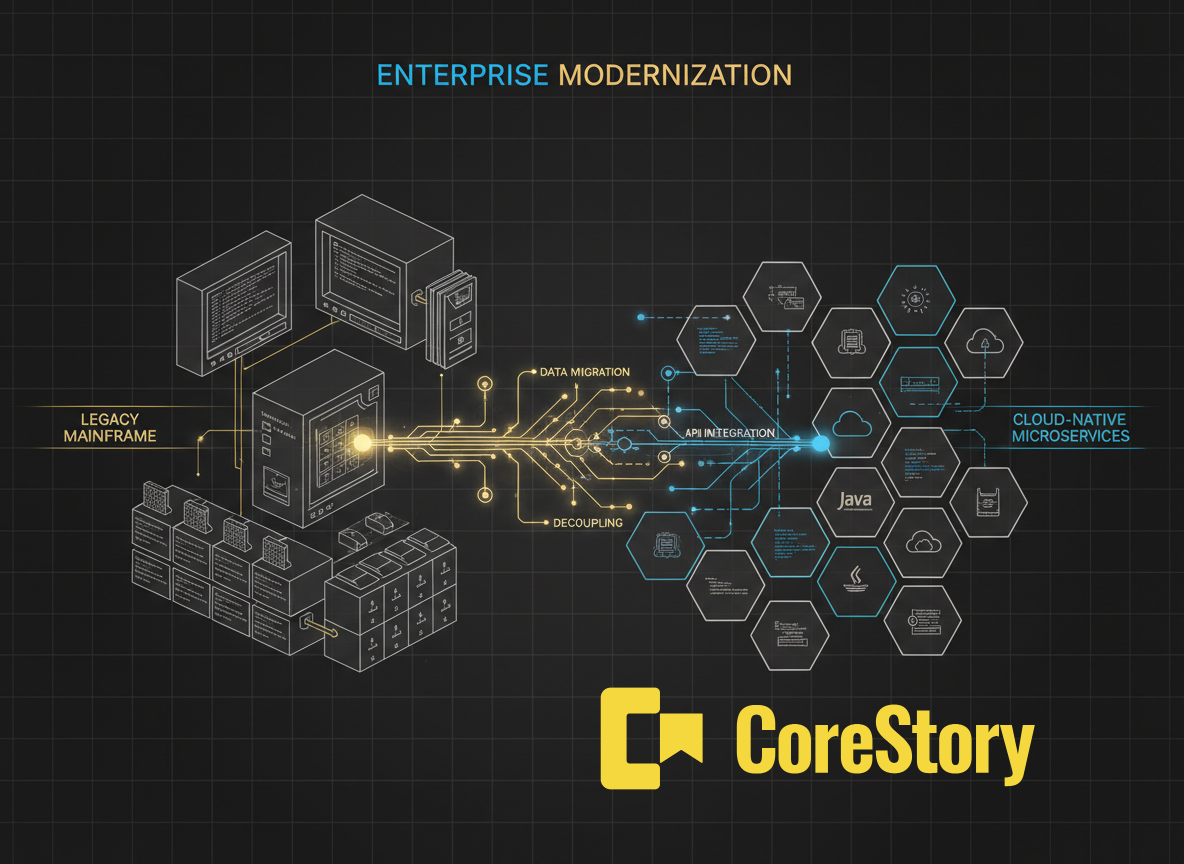
The third approach (and the one CoreStory implements) combines structural COBOL analysis with AI-powered specification generation and mandatory confidence scoring.
The key distinction is that CoreStory doesn’t just summarize COBOL code. It analyzes it structurally: parsing abstract syntax trees, resolving copybook references, tracing PERFORM chains across programs, mapping data flows through VSAM and DB2 calls, and building a Code Intelligence Model that captures the complete architecture of the system. The AI-generated specifications are derived from this structural analysis, not from reading code as text.
How the CoreStory pipeline works for COBOL
Ingestion: The entire COBOL estate is ingested — programs, copybooks, JCL, DB2 definitions, CICS maps. CoreStory supports the full mainframe ecosystem, not just the COBOL source.
Structural analysis: AST parsing extracts program structures, data definitions, control flows, and cross-program relationships. Copybook references are resolved to their actual definitions.
Intelligence model construction: A Code Intelligence Model captures the system’s architecture: which programs handle which functions, how data flows between components, where business logic is concentrated.
Specification generation: AI-assisted analysis generates structured business specifications from the intelligence model. Each specification includes what the rule does, where it’s implemented, what data it depends on, and a confidence score.
A live production example
In a production environment, CoreStory’s pipeline extracted 1,984 business specifications. Subject matter experts validated these specifications with an 85.5% approval rate. That’s not a benchmark on a test dataset. It is production output from a real system, validated by the people who maintain it.
Confidence Scoring changes the conversation to “How do we direct our expensive human experts to the parts of code that actually needs their input?” instead of involving SMEs in reviewing every single spec.
The 14.5% that SMEs flagged for revision is the system working as designed: confidence scoring identified the ambiguous cases that need review; human SMEs caught the edge cases that automated analysis couldn’t resolve; the specifications got corrected.
The final output is a validated set of business rules that modernization teams can trust (acting as “safety net” that prevents production incidents, particularly important in regulated industries), without a project-crippling human overhead.
Choosing the Right Approach
These approaches are not mutually exclusive. IBM’s own modernization stack demonstrates this: ADDI provides structural analysis, watsonx Code Assistant provides AI-assisted explanation. A practical enterprise approach might use ADDI for dependency mapping, an LLM for initial summaries, and CoreStory for validated specification generation. The question is where you need certainty.
The Validation Problem Nobody Talks About
The hardest part of COBOL business rule extraction isn’t the extraction, it’s knowing whether the extraction is correct.
Static analysis tools produce accurate structural views but don’t generate business rule documentation. LLMs generate plausible summaries but can’t guarantee accuracy. The gap between “the tool says this is the business rule” and “we know this is the business rule” is where modernization projects fail.
CoreStory’s confidence scoring addresses this directly. Every generated specification includes a confidence score that reflects the complexity of the underlying code, the ambiguity of the logic, and the completeness of the available context. High-confidence specs can be reviewed quickly. Low-confidence specs get deeper human analysis.
This isn’t a cosmetic feature. In the production example above, confidence scoring correctly flagged the most problematic specifications, the ones that SMEs ultimately revised. The validation process becomes efficient because human expertise is directed where it’s most needed, not spread evenly across thousands of specifications.
From COBOL Code to Validated Business Rules
Extracting business rules from COBOL isn’t optional — it’s the prerequisite for any modernization project that needs to preserve the logic that runs your business. The question is whether you do it manually (expensive, slow, error-prone), with an LLM (fast, cheap, unvalidated), or with a purpose-built code intelligence platform that combines structural analysis with validated specification generation.
CoreStory’s Code Intelligence Model is the third option. Real results from a real mainframe system. 1,984 business specifications. 85.5% SME validation rate. Ready for modernization planning.
See how CoreStory can help you extract valid business specifications from your COBOL codebase. Talk to an expert →
Frequently Asked Questions
Can ChatGPT or Claude extract business rules from COBOL?
They can summarize individual COBOL paragraphs, but they can’t trace cross-program logic, resolve copybook references, or validate their output. For quick exploration, LLM-assisted analysis is useful. For production modernization planning, you need structural analysis and validation.
Is IBM ADDI required before using CoreStory?
No. CoreStory performs its own structural analysis and builds a Code Intelligence Model independently. However, organizations already using ADDI can use its outputs as complementary context since the tools address different phases of the modernization pipeline.
How long does it take to extract business rules from a COBOL system?
Manual extraction for a large COBOL estate typically takes 6–18 months. CoreStory’s automated pipeline reduces the timeline significantly, though exact duration depends on the size and complexity of the system.
What about COBOL copybooks, can automated tools handle them?
Copybooks are one of the hardest challenges. A single copybook can be included in dozens of programs, and changes to the copybook affect all of them. CoreStory resolves copybook references as part of the ingestion process, mapping which programs depend on which copybook definitions. IBM ADDI also handles copybook resolution within its dependency mapping.
What’s the difference between code visualization and business rule extraction?
Visualization shows you the structure of the system: which programs call which, how data flows, where dependencies exist. Business rule extraction tells you what the system does: the logic, the decisions, the calculations, the constraints. ADDI and CAST provide visualization. CoreStory provides business rule extraction with validated specifications.