.svg)


Most legacy modernization projects don't fail because of bad engineering. They fail because no one fully understood the system they were modernizing.
The pattern is familiar: a team picks an architecture (usually microservices, because that's what the industry is doing). They start building. Six months and several million dollars in, someone discovers that orders above $500 used to require manual approval, but the new system auto-approves everything. Or that the order lifecycle spans six message-driven components across two modules, and migrating it incorrectly means lost orders.
The business rules were there all along, buried in the code. Nobody extracted them before the project started. That’s the gap that blows up modernization initiatives: not the building, but the rigorous specification that should have come first.
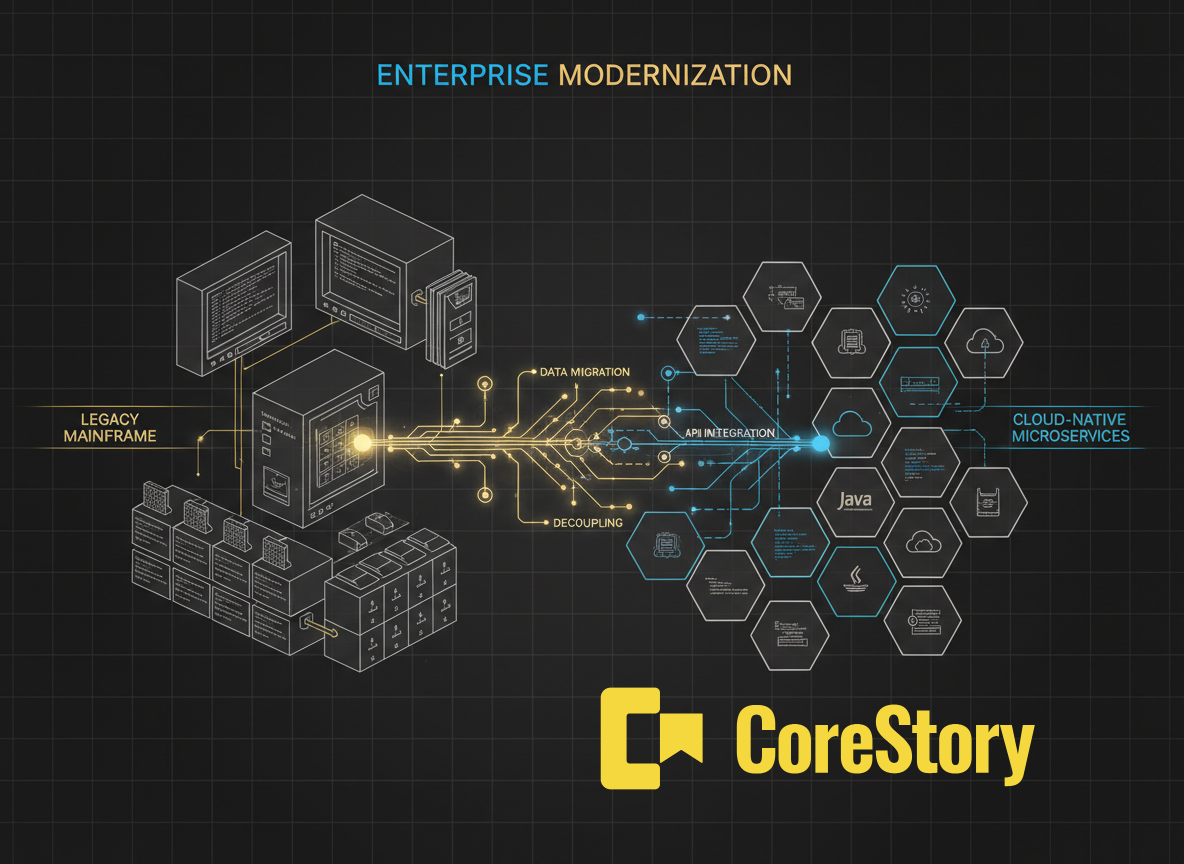
CoreStory’s Code Modernization Playbook was built to close that gap. It makes legacy codebases queryable — architecture, dependencies, business rules, risks — with answers grounded in the actual code. Not documentation (which goes stale quickly). Not tribal knowledge (which walks out the door). Not a one-shot conversation with a general-purpose AI that lacks persistent understanding of your system. The code itself, indexed and queryable over time.
To show what this looks like in practice, we ran the full six-phase playbook against Sun Microsystems’ Java Pet Store 1.3.2 — a J2EE e-commerce application from 2003 with roughly 276 classes, zero test coverage, and the full complement of legacy J2EE patterns that engineers will recognize: EJBs, message-driven beans, JMS, XML deployment descriptors.
A note on our choice of target: the Pet Store is a well-known reference application, not an enterprise system. We chose it deliberately because its patterns are real and engineers can verify every claim we make. The Pet Store’s clean boundaries are partly an artifact of its nature as a reference app. Real enterprise systems rarely decompose this cleanly — and the assessment phase in our modernization playbook becomes correspondingly more valuable, not less, when the codebase is messier.
What the playbook found
The first thing CoreStory produces as part of a modernization run is an honest assessment of the legacy system. For Pet Store, the headline readiness score was 2.2 out of 5 — not encouraging. But underneath that number, three structural findings changed the picture entirely.
First, no circular dependencies — decomposition was feasible. Second, no shared database tables — each component exclusively owned its data, eliminating the painful database-splitting phase that derails so many modernization efforts. Third, the Order Processing Center and Supplier components already communicated with the Storefront via JMS messaging. This wasn’t a theoretical service boundary. It was a boundary the original architects had drawn twenty years ago.
That third finding is an important one to note. Establishing that a boundary exists is one thing. Establishing that it’s clean — no shared tables, no backdoor dependencies, no direct calls that bypass the messaging layer — requires checking every integration point in the system. A senior architect could do this manually for 276 classes in a few days. For a system with thousands of classes, it becomes a months-long exercise. This is where persistent code intelligence adds genuine value over both manual analysis and general-purpose AI tools: CoreStory builds and maintains a complete model of the codebase’s structure, so the answer to “are these components truly decoupled?” is a query, not a research project.
Beyond the structural assessment, CoreStory extracted 95 business rules across ten domains, each with exact locations in the code. Ten were flagged as critical modernization risks. Among them: locale-specific auto-approval thresholds hardcoded in a single method, and an order lifecycle state machine spanning six message-driven beans across two modules. These aren’t the kind of rules that show up in architecture diagrams. They’re the kind that surface six months into a migration when something breaks in production.
The architecture decision
With CoreStory’s assessment and auto-extracted business rules in hand, three architecture options were evaluated:
- a modular monolith (simplest, lowest risk)
- full microservices (most impressive on paper, highest risk given zero test coverage)
- a hybrid that replatforms the tightly coupled core as a monolith while extracting two already-decoupled components as independent services along the JMS boundary
The playbook selected the hybrid. Not because it was the most impressive, and not because it was the safest. Because the evidence pointed there.
The core Storefront components share session state and orchestration logic — forcing them into separate microservices would mean rearchitecting the coupling, not just migrating it. But the Order Processing Center and Supplier were already decoupled via JMS. The boundary existed. Extracting them followed the natural grain of the architecture rather than imposing an artificial decomposition.
This is the kind of decision that typically gets made on intuition, convention, or vendor recommendation. “Let’s do microservices” because the industry says so. “Let’s replatform” because it’s safe. The playbook made it based on specific findings in the code. For a CTO approving a modernization budget, that’s the difference between a bet and an informed investment.
From plan to proof
The playbook then decomposed the work into nine packages with explicit dependency mapping and acceptance criteria referencing specific business rules by ID. The full execution produced a working Spring Boot 3.4.1 system: four deployable services (sharing a common domain library), eight modules, 117 behavioral tests — all passing.
Every one of the 95 business rules was accounted for: 62 with dedicated test methods verifying preserved or improved behavior, 8 verified through cross-domain test overlap, 7 handled implicitly by the Spring framework, 14 not applicable due to intentional architecture changes, 3 legacy behaviors intentionally improved in the modernized system, and 1 genuine gap — a reporting backend feature deprioritized because it doesn’t affect order processing correctness.
The traceability chain is what matters most for stakeholders and governance. A business owner can ask “is the $500 approval threshold preserved in the new system?” and get a definitive, traceable answer — from the business rule ID in the inventory, to the acceptance criteria in the work package, to the named test that asserts the exact behavior. That’s not a verbal assurance from the project team. It’s a verifiable chain of evidence. For regulated industries, this kind of traceability is a requirement. For everyone else, it’s how you answer the board when they ask whether the migration is actually preserving what matters.
What CoreStory did and didn’t do
CoreStory didn’t write the migration code — a separate AI coding tool handled implementation. It didn’t make the architecture decision — it presented the evidence and the team made the call. It didn’t replace the need for engineering judgment. The choice to upgrade from plain-text passwords to BCrypt, to separate queue and topic messaging topologies, to sequence work packages by coupling level — those were engineering decisions informed by CoreStory’s data but not made by it.
What CoreStory did was compress the planning phase. It turned what would normally be weeks of manual code archaeology — architects tracing references across deployment descriptors, mapping integration points, building spreadsheets of business rules from code comments and institutional memory — into hours of structured, queryable analysis. Your architects still make the decisions. They just make them faster, with complete information, and with an evidence trail that survives the project.
This is also what distinguishes CoreStory from pointing a general-purpose LLM at your codebase. An LLM can answer questions about code in a single conversation, but it doesn’t build persistent intelligence. It can’t tell you next month whether the finding it surfaced today is still accurate after a code change. CoreStory’s intelligence model is persistent and cumulative — it understands how your system behaves, and that understanding compounds as the codebase evolves.
What changes for your team
The Pet Store is a reference application — we’re not claiming this proves anything about systems with ten thousand classes and decades of accumulated complexity. But the patterns demonstrated here are the same ones that play out on enterprise modernization projects, and the implications come down to two things: less rework and less risk.
Faster modernization through less rework. The planning phase that typically takes months of manual code archaeology — architects tracing dependencies by hand, building spreadsheets of business rules from code comments and institutional memory — compresses into structured analysis measured in days. Architecture decisions come with specific justification from the code, not best-practice convention, so you’re less likely to pick an approach that needs to be revised three months in when the team discovers complexity the assessment missed. Your architects spend their time evaluating options and making decisions, not doing the manual excavation that CoreStory handles for them.
Safer modernization through less risk. Every business rule is extracted, cataloged, and traceable through to a named test — whether preserved, intentionally improved, or explicitly deferred — so the question “did we preserve the approval threshold logic?” has a verifiable answer, not a verbal assurance. Late-discovered coupling, the kind that triggers mid-project architecture pivots, is surfaced in the assessment phase rather than the execution phase. And the organizational risk where the only people who understand the legacy system are the same people you can’t pull off production support is reduced — because the system’s behavior is captured in a queryable intelligence model, not locked in someone’s head.
CoreStory doesn’t replace your engineering team or your decision-making process. It gives your people complete, evidence-based information about the system they’re modernizing — before the first line of new code is written. The decisions stay with your team. The evidence comes from the code.