.svg)

This week, Anthropic dropped a video that sent IBM's stock tumbling 13% — its biggest single-day decline in over 25 years. The demo showed Claude Code taking the AWS Mainframe Modernization CardDemo application — a credit card management system with roughly 50,000 lines of COBOL across ~100 files — and performing what amounts to a one-shot forward engineering migration into idiomatic Java.
It was slick. It was impressive to watch. And it absolutely deserves celebration.
Claude Code spawned parallel sub-agents that documented the entire codebase, generated Mermaid diagrams of data flows, produced a five-phase migration plan, and then executed it — translating COBOL copybooks into Java classes, building I/O layers, converting business logic, and standing up a dual test harness that verified bit-for-bit parity between the original COBOL output and the new Java output. Over a hundred pages of documentation materialized in about an hour. The resulting Java wasn't the grotesque transliteration we've come to expect from mechanical converters — it used proper design patterns, modern error handling, and idiomatic structure that a Java team could actually maintain.
Congratulations to the Anthropic team. This is a genuine milestone in making the vision of AI-assisted modernization feel tangible to executives who've been burned by failed migration projects for decades.
Now let me tell you what the people who actually do this work every day already know.
This Is Not New. And COBOL Was Never the Hard Part.
Here's what insiders in the legacy modernization space understand that the market apparently doesn't: LLMs have been able to read and translate COBOL for a long time. COBOL is, in many ways, an easy language for large language models. It was designed in 1959 to be readable by business people. Its verbose, English-like syntax — MOVE CUSTOMER-NAME TO WS-OUTPUT-NAME — is practically a gift to a model trained on natural language. The CardDemo repository is a well-structured, didactic sample application that AWS built specifically to showcase their mainframe modernization services. It has clean separation of concerns. It has relatively straightforward batch processing flows. It's the kind of codebase where a one-shot migration should work.
The commenters on Hacker News captured this perfectly. As one put it: "Software automatically translating COBOL to Java has been around for a long time. So there is zero value add using AI for this." Another noted that the real challenge isn't the translation itself but "replicating all that existing customers expect and depend on, including what's unspecified."
IBM's Rob Thomas responded directly: "Translation captures almost none of the actual complexity. Decades of hardware-software integration cannot be replicated by moving code."
He's partly right, though his motivations are obviously defensive. But the core insight is correct: understanding COBOL syntax was never the bottleneck. The bottleneck is everything else.
What "Everything Else" Actually Means
Let's talk about what real enterprise COBOL modernization looks like — not the demo, but the production reality at a top-20 bank or a federal agency.
Scale. The CardDemo is ~50,000 lines across 100 files. A mid-tier insurance company's core platform might have 15 million lines of COBOL. A major bank? 50 to 100 million lines. Some government systems exceed 200 million. These aren't clean repositories with clear boundaries — they're geological strata of code written by thousands of developers over five decades, with layers of patches, workarounds, regulatory amendments, and undocumented behavioral modifications stacked on top of each other.
Implicit dependencies. Real COBOL systems have coupling that doesn't appear in any call graph. Shared VSAM files that create invisible data contracts between programs. JCL job streams that orchestrate execution order in ways that constitute business logic. CICS transaction definitions that determine runtime behavior. DB2 stored procedures that contain critical calculations. IMS hierarchical database structures that enforce business rules through their schema. None of this shows up when you analyze COBOL source code in isolation.
The "last 20%" problem. In any modernization, the first 80% of the code translates cleanly. It's the remaining 20% — the edge cases, the undocumented behaviors, the assembly-language subroutines called from COBOL, the programs that rely on platform-specific EBCDIC sorting behavior, the packed decimal arithmetic that produces slightly different rounding than IEEE 754 floating point — that consumes 80% of the effort and causes 100% of the production incidents.
Institutional knowledge that exists only as runtime behavior. The most dangerous business logic in legacy systems isn't written in any source file. It's emergent behavior arising from the interaction of hundreds of programs, job schedules, operator procedures, and environmental configurations. When a bank's overnight batch run processes transactions in a specific order because of JCL sequencing that was set up in 1987, and that ordering affects how interest is calculated across accounts — that's business logic. It's not in the COBOL. It's in the infrastructure. And no amount of source code analysis will find it.
Where Claude Alone Hits Its Ceiling
Claude Code is extraordinary at what it does. But let's be precise about the boundaries:
Context window limits are real. Even with Claude's generous context, you cannot fit 15 million lines of COBOL into a single session. The sub-agent architecture shown in the demo is clever, but it fundamentally operates on isolated slices of the codebase. Each agent sees a piece. Nobody sees the whole. Cross-cutting concerns — the kind that cause production failures — live in the gaps between those isolated context windows.
No runtime behavioral analysis. Claude reads source code. It doesn't observe how systems actually behave in production. It can't tell you that Program X produces different output on the third Tuesday of each month because of a leap-year edge case in the date routine that was patched in 1994 and never documented. It can't detect that the ordering of records in an output file matters to a downstream consumer that was written by a different team in a different decade.
No organizational knowledge. The business rules encoded in COBOL were defined by people who are now retired or deceased. Some of those rules were regulatory requirements from agencies that have since been reorganized. Some are competitive advantages that the business doesn't even realize are encoded in their software. Claude can't interview stakeholders, cross-reference with compliance documentation, or validate against the institutional memory that lives in the heads of the three remaining people who understand the system.
No incremental validation at scale. For a 100-file demo, you can verify output parity by running both versions and comparing. For a system that processes 500 million transactions per day across 12,000 programs with real-time and batch components, the validation problem is orders of magnitude more complex. You need regression test suites that cover actual production behavior, not just the happy path.
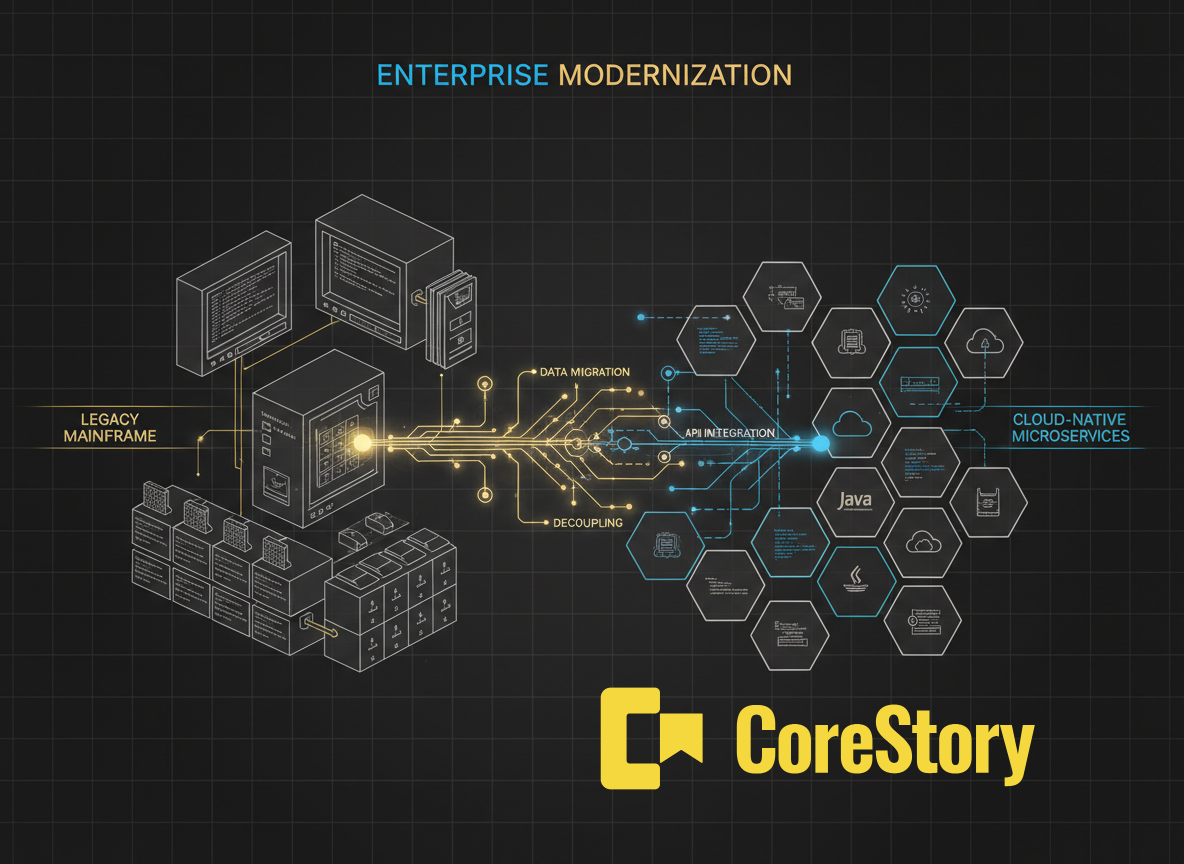
What CoreStory Does Differently — And Why It Matters
This is where I'm going to be direct about what we've built at CoreStory, because the gap between what the demo shows and what production requires is precisely where our technology operates.
CoreStory is not a competitor to Claude. We're a context intelligence layer that makes Claude (and every other AI coding agent) dramatically more effective at exactly the kind of work that the demo hand-waves past. Here's how:
Living specifications, not static documentation. When Claude Code documented the CardDemo, it produced excellent Markdown files — a snapshot in time. CoreStory generates living specifications from codebases: structured, queryable representations of business rules, data flows, architectural patterns, and cross-cutting concerns that stay synchronized with the code as it evolves. When you run Claude on top of CoreStory's spec output, it's not working from a flat description — it's working from a deep, structured understanding of the system's actual semantics.
Cross-codebase traceability. In production, COBOL programs don't live alone. They interact with JCL, CICS definitions, DB2 schemas, MQ configurations, and often with code written in other languages. CoreStory maps these relationships at a level of detail that goes far beyond call graphs — we build traceability matrices that connect business rules to the specific code, configuration, and infrastructure that implements them. When you migrate a COBOL program, CoreStory can tell you exactly which downstream systems, data contracts, and behavioral assumptions will be affected.
Rule extraction and validation. One of the hardest parts of legacy modernization is answering the question: "What does this system actually do?" Not what the code says — what business rules are encoded in its behavior. CoreStory extracts these rules, normalizes them into a structured format, and enables subject matter expert validation before migration begins. This is the step that separates a demo from a production migration.
Nondeterministic behavior detection. Legacy systems often contain code paths that produce different results depending on environmental conditions — date-dependent logic, platform-specific arithmetic, ordering-dependent processing. CoreStory specifically identifies these patterns and flags them as migration risks. This is the kind of subtlety that will pass a bit-for-bit test on sample data and then blow up spectacularly in production when it encounters the edge case you didn't test.
The Architecture That Actually Works: Claude + CoreStory
Here's what a production-grade modernization looks like when you combine Claude's capabilities with CoreStory's context intelligence:
Phase 1: Deep Discovery (CoreStory) CoreStory processes the entire codebase — all 15 million lines, all languages, all configuration — and generates a comprehensive specification. This includes business rule extraction, dependency mapping, risk identification, and a structured representation of the system's actual behavior, not just its source code.
Phase 2: Migration Planning (Claude + CoreStory context) Claude operates with CoreStory's specifications as context, enabling it to generate migration plans that account for cross-cutting concerns, implicit dependencies, and behavioral risks that source code analysis alone would miss. The plans include explicit callouts for areas requiring SME validation.
Phase 3: Incremental Migration (Claude + CoreStory validation) Claude performs the code translation — it's genuinely excellent at this. But each translated component is validated against CoreStory's specifications to ensure that business rules are preserved, edge cases are handled, and behavioral parity is maintained. CoreStory can flag when a translation has subtly altered a business rule, even when the code looks syntactically correct.
Phase 4: Continuous Verification CoreStory monitors the migrated system's behavior against its specification, catching drift and regression in real-time rather than waiting for production incidents to reveal problems.
This isn't theoretical. This is the approach we're building and validating with enterprise customers who have tens of millions of lines of legacy code and zero appetite for the kind of production failures that make headlines.
The Bottom Line
Anthropic's demo is a watershed moment for awareness. It showed the world that AI can meaningfully participate in legacy modernization, and it did so with enough polish to move markets. That matters. The more people understand that COBOL migration doesn't have to be a decade-long death march, the more organizations will actually begin the journey.
But if you're a CIO watching that video and thinking "we can just point Claude at our mainframe and be done by Q4" — please talk to someone who has actually done this work. The demo migrated a clean, well-structured, 50,000-line sample application. Your system is a 30-million-line labyrinth built by 2,000 people over 40 years, running on infrastructure that encodes business logic in its configuration, with regulatory requirements that nobody has fully cataloged since 2003.
You need Claude's intelligence. You absolutely do. It's the best code generation engine available.
But you also need the deep, structured, cross-cutting understanding of your system that only a purpose-built context intelligence layer can provide. That's what CoreStory delivers. Not instead of Claude — through Claude, around Claude, making every token Claude generates more informed, more accurate, and more trustworthy.
The future of legacy modernization isn't AI alone. It's AI that knows what it's looking at.
CoreStory is the context intelligence layer for AI-powered code modernization. We generate living specifications from codebases of any size, enabling AI coding agents to work with deep understanding of business rules, dependencies, and behavioral constraints. Learn more at corestory.ai