.svg)

Understanding the Positive Impact of CoreStory on Agent Performance on the Hardest SWE-bench Verified Tasks
Study Period: December 2025
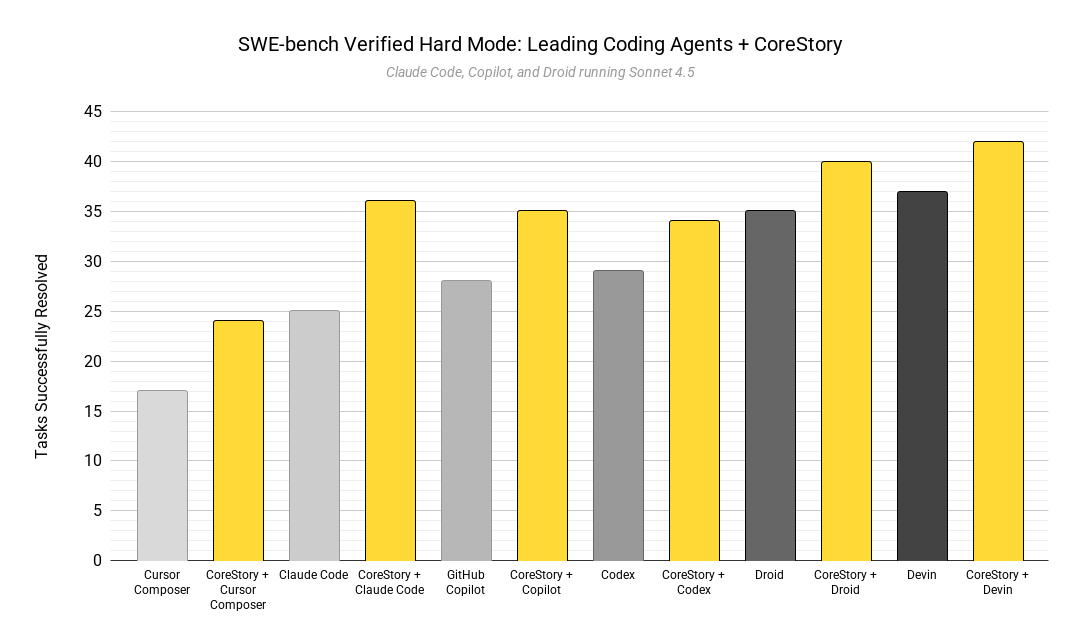
Benchmark: SWE-bench Verified — Hard Mode (45 tasks)
Agents Evaluated: Claude Code, Cursor, GitHub Copilot, Codex, Droid, Devin
Evaluation Design: Controlled A/B comparison (baseline agent vs. CoreStory-augmented agent)
Executive Summary
The following is a controlled, cross-agent evaluation of CoreStory, a code intelligence platform that provides architectural context and specifications to AI coding agents via Model Context Protocol (MCP).
Across six leading AI coding agents and 45 of the hardest tasks in SWE-bench Verified, CoreStory consistently and materially improved agent performance. All agents showed measurable uplift when augmented with CoreStory, with relative improvements ranging from +14% to +44% and an average relative uplift of ~25%.
More importantly, this evaluation identifies why those improvements occur. CoreStory does not primarily help agents debug failing implementations. Instead, it prevents agents from pursuing incorrect solution paths in the first place by supplying architectural and semantic context that is not recoverable from local code inspection alone.
These results are consistent across agents, repositories, and task types, indicating that CoreStory addresses systematic, model-agnostic failure modes in AI-assisted software maintenance.
1. Results Overview
1.1 Performance Summary
Key observation: Performance gains are universal across agents with very different architectures, autonomy levels, and underlying models.
1.2 Aggregate Statistics
The fact that over half of the task set saw at least one agent flip from failure to success indicates that CoreStory’s impact is not limited to edge cases.
2. Baseline Capability vs. Uplift
2.1 Non-Linear Relationship
The relationship between baseline agent capability and CoreStory uplift is non-linear, not monotonic.
Agents with mid-range baseline performance benefit the most from architectural context injection.
2.2 Implication for Teams
CoreStory provides maximum leverage when agents are:
- capable enough to implement correct solutions
- but insufficiently oriented in unfamiliar architectures
This range (roughly 50–70% baseline success) aligns closely with most production-deployed AI coding agents today.
3. Cross-Agent Convergence as Validation
A key strength of this evaluation is cross-agent convergence: independent agents making the same incorrect assumptions — and receiving the same corrective guidance from CoreStory.
3.1 Multi-Agent Flip Tasks
When multiple agents converge on the same wrong solution, the failure is not model-specific — it is architectural.
3.2 Deep Dive: sphinx-8548
Symptom: Missing docstrings for inherited attributes
Observed agent behavior: All three agents initially attempted to fix docstring retrieval logic.
Actual root cause: Attributes were never collected during member enumeration.
This is a classic pipeline misattribution error:
- downstream symptom
- upstream cause
CoreStory redirected all three agents to the same upstream fix (get_class_members()), preventing hours of wasted implementation effort.
4. Value Mechanism Taxonomy
Analysis of all 39 “flips” reveals five recurring mechanisms.
4.1 Mechanism Distribution
These mechanisms frequently overlap within a single task.
5. Primary Mechanisms
5.1 Wrong Solution Prevention (72%)
Failure mode
Agents fix symptoms instead of causes when architectural boundaries are unclear.
Why models fail here
Local reasoning is rational given limited architectural visibility and available context.
What CoreStory supplies
Pipeline-level orientation — where data enters, flows, and is filtered.
Result
Agents abandon incorrect approaches before implementation.
This is the dominant source of CoreStory’s performance gains.
5.2 Hidden Dependency Discovery (46%)
Failure mode:
Non-local coupling causes changes in one component to affect unrelated behavior.
Why models fail here:
Dependencies are implicit, undocumented, and often instantiated indirectly.
What CoreStory supplies:
Semantic dependency graphs that expose propagation paths.
Example: django-15503
With CoreStory, both agents independently discovered that KeyTransformIsNull internally constructs HasKey, a dependency invisible via local inspection.
5.3 Multi-Location Fix Identification (41%)
Failure mode:
Partial fixes in distributed logic lead to fragile or inconsistent behavior.
What CoreStory supplies:
Complete enumeration of all participating locations.
Example: sympy-12489
A correct fix required coordinated changes across 15+ locations.
5.4 Semantic Distinction Revelation (36%)
Failure mode:
Agents confuse constructs with identical syntax but different semantics.
Examples:
- array index vs. object key
- replace vs. optimize-through semantics
- alias vs. annotate behavior
CoreStory clarifies semantic intent, not just structure.
6. Efficiency Impact
6.1 Time Reduction (Agent-Reported)
Higher-baseline agents show smaller marginal gains, consistent with ceiling effects. Given agents’ difficulty with translating their work into actual time, it’s best to understand these as relative reductions in implementation effort and token expenditure.
6.2 Files Avoided
Across 39 flips, agents avoided reading an estimated 300–500 files, replacing exploratory code archaeology with targeted architectural queries.
7. The “Senior Engineer Effect”
Across all agents, CoreStory was independently described as equivalent to “a senior engineer giving a five-minute architectural walkthrough.”
This reflects the specific class of context CoreStory provides:
- system boundaries
- data flow
- implicit contracts
- historical patterns
- known architectural traps
8. Implications for Adoption
When CoreStory Delivers Highest Value
- Large, unfamiliar codebases
- Pipeline-heavy frameworks
- Multi-component bugs
- Mid-capability agents (50–70% baseline)
When Value Is Lower-Impact
- Trivial, single-file changes
- Extremely high-baseline agents
- Small, fully documented systems
9. Conclusion
This evaluation demonstrates that architectural context injection is a first-order driver of AI coding agent performance on complex software maintenance tasks.
CoreStory:
- improves success rates by ~25% on average
- prevents predictable, systematic failure modes
- operates consistently across agents and domains
- requires no changes to the agents themselves
For teams deploying AI coding agents on real production systems, these results indicate that architectural intelligence is not an optimization layer — it is foundational infrastructure.
Ready to drive better performance from your coding agents with CoreStory? Try CoreStory for free today..