.svg)

The State of Agentic Code Generation
If the SWE-bench leaderboard is to be believed, generative AI models are getting better at writing code with each major release. However, the practical experience of using coding agents remains underwhelming in at least one specific regard: they can’t yet perform human-quality work on large codebases.
The reasons for this deficit are simple to understand but difficult to solve. We generally observe three main causes of failure:
- Context and memory constraints: agents can only gather and retain a limited amount of data in their session memory, which causes them to lose the thread as they work.
- Navigation challenges: most agents attempt to reverse-engineer architectural knowledge directly from code on the fly, resulting in an incomplete and flawed understanding of a system’s structure.
- Reasoning limitations: agents blow out their context trying to solve problems related to complicated logic or spaghetti code, exacerbating limitation #1.
We’ve built CoreStory to improve the performance of human and AI engineers when working with large codebases. We've done this because much of the code that runs our world today is inside massive, aging monoliths – places where generalized AI models have yet to make much of an impact at all.
Solving this technical challenge has the potential to deliver sweeping macroeconomic benefits for enterprises in all sectors: more successful modernizations, lower costs of enterprise application maintenance, and fewer devastating service outages and security failures.
That’s where we’ve placed our bullseye. But how can we know when we’ve hit it?
Introducing SWE-Bench Verified Hard Mode
Public benchmarks are the method by which the industry tracks generative AI gains, and the most widely cited benchmark for coding agents is SWE-bench. SWE-bench has a few different flavors; we’re partial to SWE-bench Verified, a curated subset of 500 SWE-bench tasks that have been essentially “cleaned up” following review by human engineers.
However, when it was time to start benchmarking CoreStory’s agent augmentation capabilities, we didn’t see much utility in using the full SWE-bench Verified dataset. CoreStory’s code intelligence is specifically designed to assist agents operating at the frontier of what’s possible for generative AI; we wouldn’t learn much by helping agents solve tasks that they can already solve.
So, we curated our own subset of SWE-bench Verified, which we call SWE-Bench Verified Hard Mode. Its makeup is straightforward, consisting of
- the 42 tasks in the SWE-bench Verified dataset estimated to take between 1-4 hours, plus
- the 3 tasks in the SWE-bench Verified dataset estimated to take >4 hours
That’s 45 tasks in total, excluding all SWE-bench Verified tasks estimated to take under 1 hour to resolve.
Our rationale here is simple: the hardest tasks are the most valuable to teams and the most challenging for AI to resolve. If CoreStory enables coding agents to successfully resolve harder tasks, then those agents will deliver more value for users.
Running SWE-Bench Verified Hard Mode
This evaluation uses a simple A/B design. Each coding agent is asked to solve every Hard Mode task:
- Once on its own, and then
- Once with CoreStory augmentation
The CoreStory-assisted runs differ in only two ways:
- CoreStory is available via MCP as the sole augmentation
- The agent is given a generic instruction explaining how CoreStory should be queried for architectural guidance
No skill files, hints, oracle patches, previous logs, or additional tools are introduced. The goal is to isolate CoreStory as the only variable.
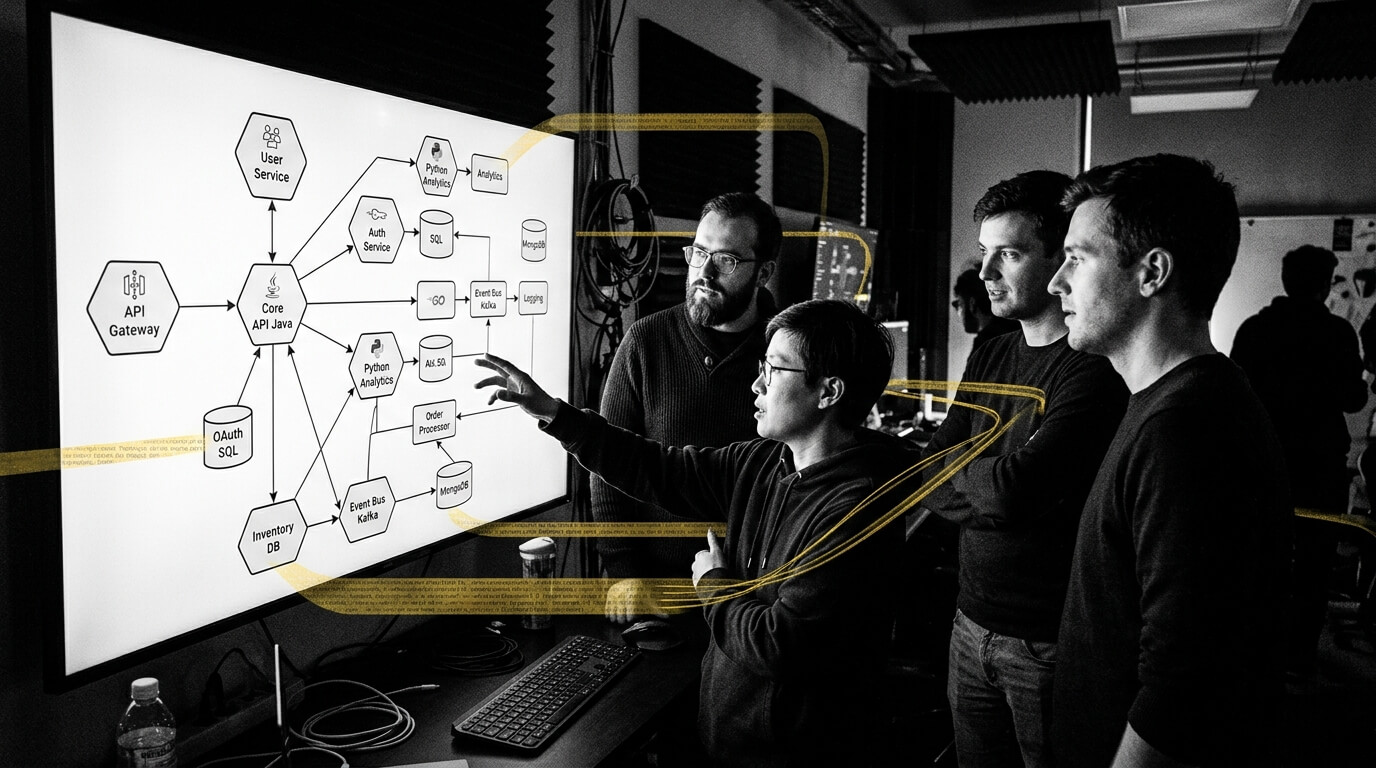
How CoreStory Augments Coding Agents
Before any task begins, CoreStory ingests the target repository and builds a queryable intelligence model of the codebase covering architecture, data flow, specifications, and implicit relationships. We call these outputs code intelligence.
Agents can pull from this intelligence during implementation by asking questions like:
- How does this subsystem work architecturally?
- What components are involved in this behavior?
- Are there hidden dependencies I should be aware of?
CoreStory does not intervene automatically or steer agents toward a specific solution. It plays the role of a senior engineer who already understands the system, answering questions when asked. The agent remains fully responsible for implementation.
What We Found
We ran six leading coding agents through Hard Mode with and without CoreStory:
- Claude Code (Anthropic)
- Codex (OpenAI)
- GitHub Copilot (GitHub)
- Devin (Cognition)
- Cursor Composer (Cursor)
- Droid (Factory)
Claude Code, GitHub Copilot, and Droid utilized Claude Sonnet 4.5 as their underlying model. Codex utilized Codex 5.1 Max. Session enhancements such as codebase indexing, “extended thinking”, and web browsing were disabled for all sessions.
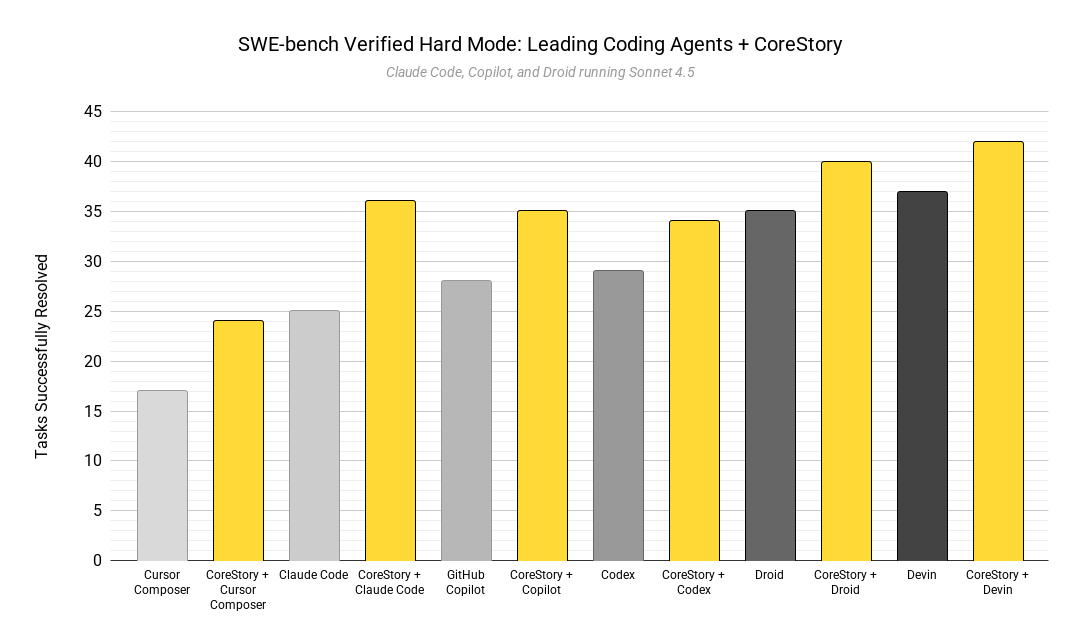
CoreStory’s Impact
CoreStory improved performance for every agent tested.
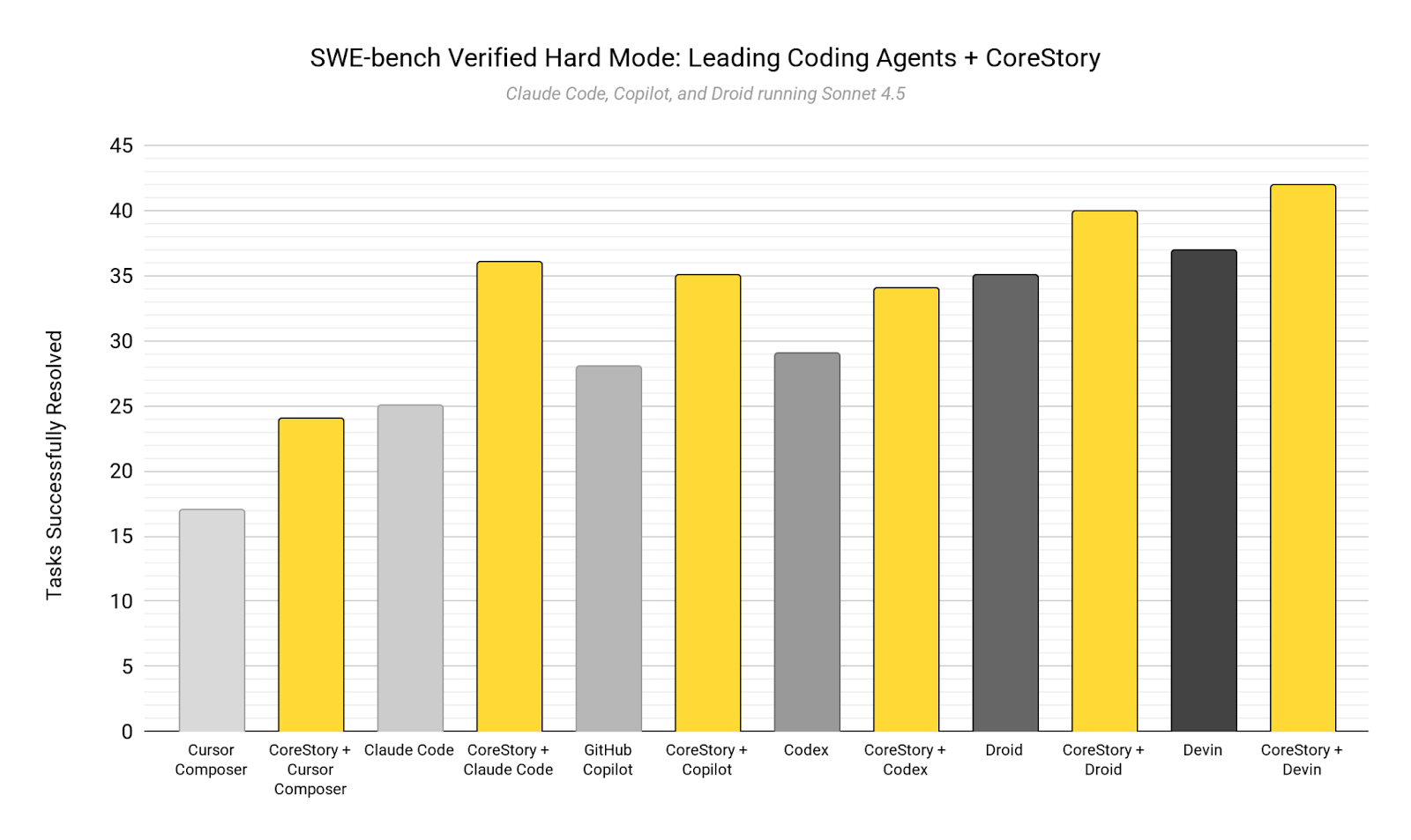
Relative uplift ranged from +14% to +44%, depending on the agent’s baseline capability.
More importantly, the improvements weren’t confined to a single tool, model family, or interaction style. CoreStory consistently raised success rates across very different agents, from lightweight assistants to highly autonomous systems.
Why CoreStory Works: Preventing the Wrong Solution
The most important insight from the experiment wasn’t just that agents improved, but how.
In nearly three quarters of successful fail-to-pass flips, CoreStory didn’t help agents debug a failing implementation. Instead, it prevented them from pursuing the wrong solution in the first place.
Across dozens of tasks, agents repeatedly showed the same failure pattern:
- Observe a symptom
- Reason toward the most obvious code location
- Implement a plausible fix
- Fail tests—or worse, introduce subtle bugs
CoreStory intervenes upstream, redirecting agents before time is wasted. It helps them understand:
- Where in the pipeline the bug actually lives
- Which components are involved (and which are not)
- What hidden dependencies or semantic distinctions matter
In one particularly illustrative task, three independent agents all made the same incorrect assumption about where a bug lived. With CoreStory, all three independently corrected course—fixing the same upstream architectural issue instead of chasing symptoms downstream.
This pattern repeated across frameworks, languages, and agents.
The Sweet Spot
Another interesting finding was related to where CoreStory delivers the most value.
Agents with mid-range baseline performance—roughly 50–65% success without assistance—saw the largest gains, improving by 25–44%. These agents are capable enough to implement solutions correctly, but lack the architectural understanding needed to choose the right solution path.
Very strong, specialized agents (already succeeding ~80% of the time) still improved, but by a smaller margin. They simply had fewer failures left to correct.
The worst-performing baseline agent, Cursor Composer, is a bit of an outlier here. It’s a very new agent, and it’s built for speed, which reduces the time it spends reasoning through complex issues. Even so, CoreStory improved its performance to a level consistent with leading reasoning models.
These outcomes suggest that CoreStory is best understood as a capability multiplier for coding agents. It doesn’t replace reasoning or coding ability—rather, it amplifies it when agents are operating near their limits.
The “Senior Engineer" Effect
When asked to describe CoreStory’s role, every agent used variations of the same metaphor:
“It felt like a senior engineer giving me a five-minute architectural walkthrough.”
That’s by design. CoreStory provides exactly the kind of context a senior architect or engineer offers:
- System boundaries and data flow
- Implicit contracts between components
- Existing patterns already used elsewhere
- Common pitfalls where symptoms mislead about root causes
In multiple cases, agents passed entire test suites on the first attempt, without running tests or iterating—simply because they understood the system correctly before writing code.
Opportunities for Improvement
Based on our session log analysis, we’ve identified a small set of high-leverage improvements that materially increase agent success on complex tasks. We’re focused on adding concrete implementation patterns (not just diagnosis), clearer guidance for multi-component changes, and smarter calibration of guidance depth—so agents solve the right problem at the right level of sophistication. Together, these improvements directly address the failure modes we observed and are expected to drive meaningful near-term performance gains on this benchmark.
Note that the best-performing pairing, CoreStory and Devin, is approaching a 100% success rate on the hardest tasks in the SWE-bench Verified dataset. It’s reasonable to hypothesize that this level of performance on hard tasks will generalize to the full set of tasks in the broader benchmark, give or take the natural variance that comes with non-deterministic tools like LLMs.
Should we achieve that result in the near future, we will need to identify a new benchmark for CoreStory-assisted agents to “graduate” into.
What a 25% Improvement Actually Means for Teams
The headline result of SWE-bench Verified Hard Mode is an average ~25% relative improvement in agent success on complex tasks. On its own, that number is abstract. Its real significance becomes clearer when translated into day-to-day engineering work.
A 25% improvement does not mean engineers write code 25% faster in every situation. It means that on the hardest, most failure-prone work—the work that normally stalls progress—agents succeed materially more often.
In practice, that shows up in several ways.
First, fewer dead-end attempts. Much of the cost of complex engineering work is not time spent typing code, but time spent pursuing solutions that turn out to be wrong. When agents repeatedly fix the wrong layer, miss hidden dependencies, or misunderstand system flow, humans are pulled in to debug, reorient, or restart. Preventing those failures removes entire cycles of wasted effort.
Second, more work completed without escalation. When agents can correctly navigate architecture, fewer tasks need to be handed off to senior engineers for intervention. That changes how teams allocate attention: senior engineers spend less time unblocking work and more time designing systems, reviewing high-impact changes, or moving modernization efforts forward.
Third, complex work becomes schedulable instead of risky. Teams already use AI agents successfully on routine tasks. The bottleneck is complex, legacy, or cross-cutting changes—exactly where failure rates are highest. Improving agent reliability on those tasks means more of the backlog becomes viable for automation, rather than deferred or manually handled “just to be safe.”
Finally, velocity improves without increasing risk. Productivity gains that come from undisciplined AI adoption tend to surface later as bugs, regressions, or outages. The improvement measured here comes from better understanding, not faster guessing. That matters in production systems where correctness is more valuable than speed alone.
Seen this way, a 25% improvement compounds. It shortens cycles, reduces interruptions, lowers the cognitive load on senior staff, and expands the set of problems teams are willing to hand to agents at all.
Why This Matters Now
Most teams evaluating AI-assisted development focus on model capability: better reasoning, larger context windows, or more autonomous behavior. Those improvements help, but they don’t address the core constraint exposed by Hard Mode.
Agents don’t primarily fail because they can’t write code. They fail because they don’t understand the system they’re modifying.
CoreStory changes that starting point. By supplying architectural and specification-level orientation up front, it shifts agent behavior from exploration-driven to understanding-driven. The result isn’t just higher benchmark scores—it’s a different risk profile for using agents on real systems.
For teams already using AI coding tools, the question isn’t whether agents will get better over time. They will. The question is how much value you leave on the table while they remain blind to system architecture.
Our findings on Hard Mode suggests that gap is measurable—and closable.
Are you ready to make your agents smarter with CoreStory? Join our waitlist for self-serve usage.
---
Additional Experiment Design Notes
This section contains particulars about the benchmark process itself. It's strictly intended for the curious. For a full deep-dive analysis, see this report.
To better reflect real-world usage conditions and our own ambitions for CoreStory, our benchmark differs from SWE-bench Verified in a few critical ways:
- Full agentic workflow evaluation
Rather than evaluating raw agent patch generation by base LLM models, Hard Mode is designed to evaluate agent harnesses used by the majority of AI-native dev teams today – meaning they are free to employ multi-step reasoning, file navigation, and tool calls, though not internet browsing or other integrations besides CoreStory.
- Task assignment via a markdown file
We provide the full task description, including hints and test patches (and, for the CoreStory-assisted tasks, generic CoreStory usage guidance) in a templated markdown file. We exclude the oracle patch or any task-specific guidance for all runs.
- CoreStory enhancement via MCP
Because we’re assessing agents, the CoreStory-assisted runs utilize Model Context Protocol (MCP) to enable the agent to communicate with CoreStory.
- Generic nudges allowed
Agent sessions can run extremely long on these tasks, which increases the risk of workflow interruptions for reasons unrelated to the agent’s reasoning capacity. For this reason, human intervention was permitted in the form of generic, standardized “nudges” such as “Are you still working?” or “Proceed”.
- Agents may run tests locally
Agents had access to the test_patch.diff file included with each task and were free to attempt to run test suites included in the base commit. Indeed, most successful runs saw the agents correctly run the tests and iterate against those tests.
- Captures CoreStory usage logs
Agents are asked to track their CoreStory usage while they work and report on it at the end of the session.
- Offline patch creation, but online patch eval
Although the actual creation of the patch occurs in an offline (but still controlled and supervised) environment, we still evaluated all tasks using the official SWE-bench Docker harness. No partial credit was granted per task; agents must pass all tests in order to score a successful resolution.