.svg)

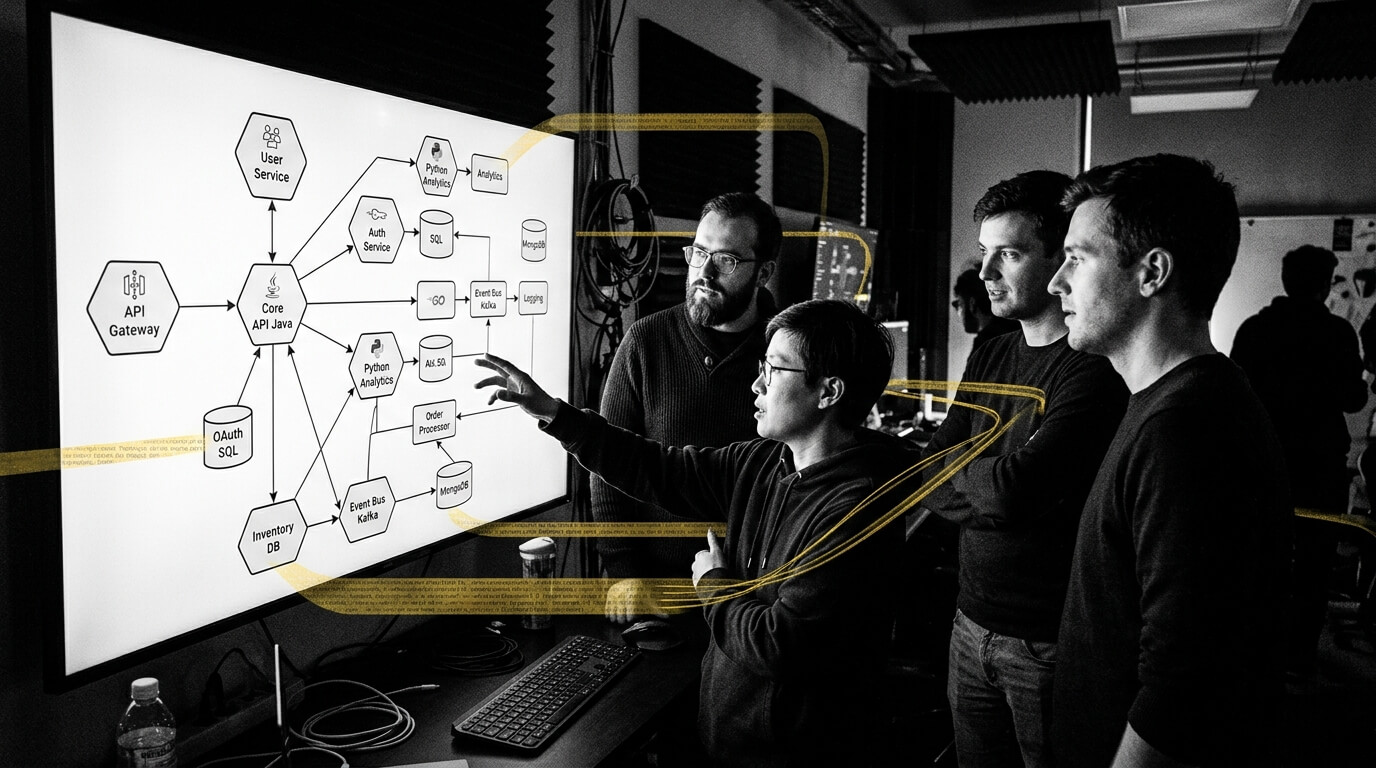
Large Production Systems Are Not Single-Language Problems
Walk into any engineering organization running systems at scale and you won't find a neat, single-language codebase. You'll find a layered ecosystem built across years: Java microservices handling core business logic, Python powering data pipelines and ML inference, Go running high-throughput APIs, Ruby on Rails serving the customer-facing product, C++ embedded in performance-critical processing, SQL stored procedures encapsulating decades of business rules, and Bash scripts holding together the operational glue.
A typical enterprise production system contains at least six to ten distinct languages interleaved across thousands of components. This polyglot reality is not an edge case. It's the inevitable result of technology choices made at different points in time, by different teams, for different reasons — all of which still need to work together in production.
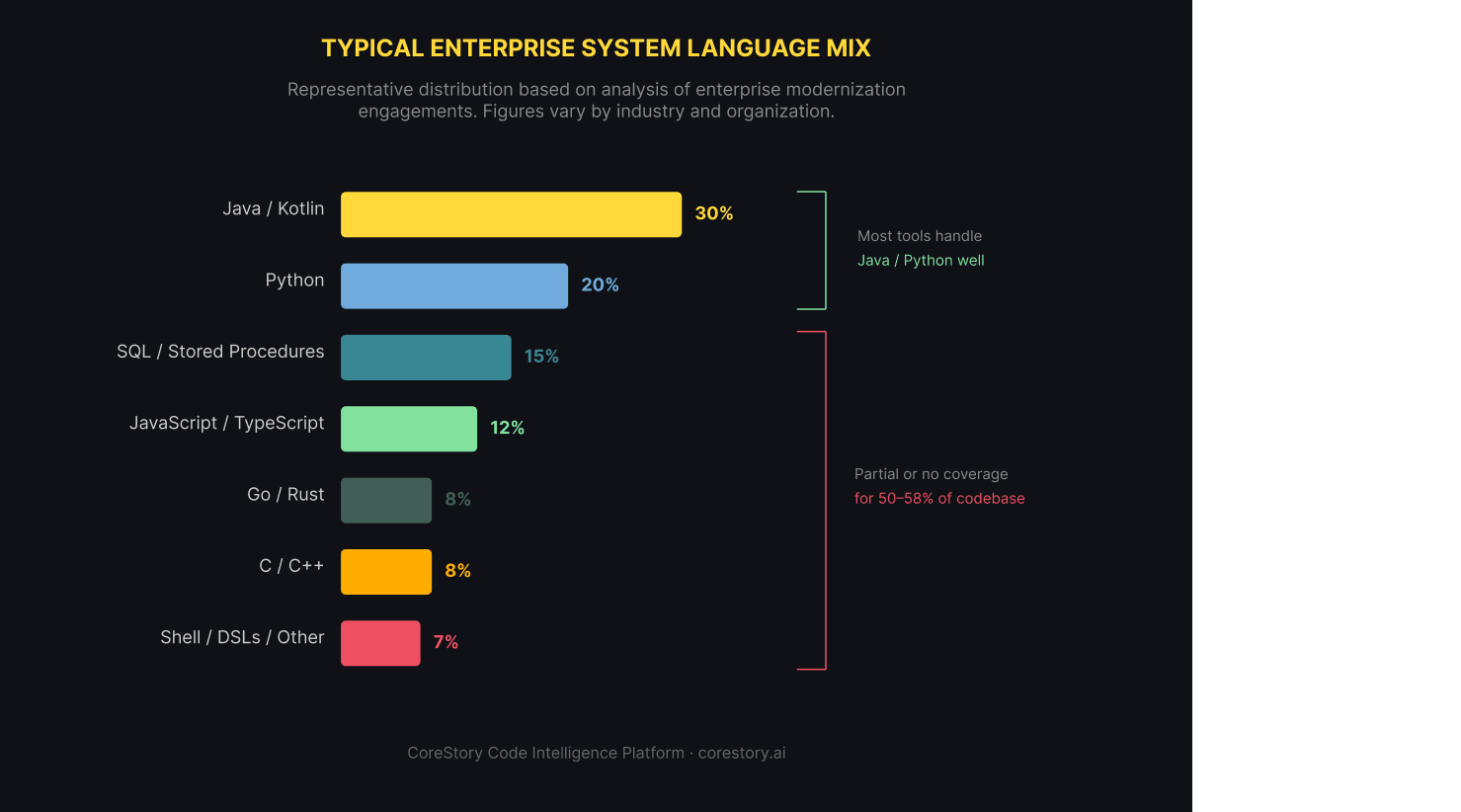
Yet the code intelligence tooling market has historically focused on isolated languages or paradigms, treating cross-language analysis as an advanced feature rather than a baseline requirement.
That creates a fundamental gap. When a significant portion of your production system is written in languages your intelligence tool doesn't fully understand, you don't have a complete picture — you have a partial view with blind spots wherever system components cross a language boundary.
The Competitive Landscape: Most Tools Were Built for One Context
The pattern across the market is strikingly consistent. Whether the approach is static analysis, fine-tuned LLMs, or symbolic reasoning, most tools start from a single language or ecosystem and build outward — slowly, one parser at a time.

GitHub Copilot offers broad language coverage for code completion but operates at the file level — it has no model of how your Python data pipeline connects to the Java service that consumes it. Sourcegraph provides powerful code search and structural analysis but doesn't reason about cross-language system behavior. Amazon Q Developer focuses on Java and Python with partial support elsewhere. Swimm offers language-agnostic documentation through static analysis but doesn't address cross-system intelligence. Generic LLM tools like ChatGPT and Claude are limited to what fits in a context window — they have no persistent model of your specific codebase.
The key insight here isn't that these tools are poorly built. It's that their architecture forces linear scaling. Each new language requires a dedicated parser or fine-tuned model, months of R&D, and ongoing maintenance. That's an architectural constraint, not a product strategy choice.
CoreStory treats language support as an architecture decision rather than a feature add — building agents that reason about any language, not parsers hardcoded for one.
What Are Polymorphic Agents?
A polymorphic agent is an agent that dynamically adapts its reasoning strategy, tool selection, and analysis technique based on the language, structure, and context it encounters. Rather than running a fixed analysis pipeline, each agent evaluates what it's looking at and selects the right approach in real time.
This works through three core capabilities.
Language-aware reasoning. When a polymorphic agent encounters a code artifact, it doesn't just identify the language — it identifies the dialect, the framework, the version era, and the specific patterns in use. A Python 2 data processing script gets different treatment than a Python 3 async FastAPI service, because they have different concurrency models, dependency patterns, and runtime behaviors. A Java Spring Boot service using REST is analyzed differently than one using gRPC or message queues. Critically, this version awareness also applies within a single codebase: a system running some services on Java 8 and others on Java 17 gets version-specific analysis for each, rather than a one-size-fits-all parse that misses what changed between them.
Dynamic tool selection. Instead of relying on a single parser per language, polymorphic agents choose from a toolkit of analysis techniques: AST parsing for structured languages with formal grammars, pattern matching for framework-specific idioms and DSL extensions, symbolic execution for tracing control flow through complex conditional logic, and LLM inference for extracting business intent from function names, comments, and structural patterns. Importantly, the agent tracks which technique produced each finding — deterministic results from AST parsing and symbolic execution are marked as high-confidence facts, while LLM-inferred intent is marked as probabilistic and flagged for human review.
Cross-language context fusion. This is where the architecture creates its most significant advantage. When a Python data pipeline passes results to a Java processing service through a Kafka topic, or when a COBOL CICS transaction writes to a DB2 table and a downstream Java service reads the same table via JDBC to populate a REST API, polymorphic agents trace the full data flow — fusing context across language and runtime boundaries into unified specifications. Single-language tools stop at exactly these integration points, leaving the most important parts of system behavior uncharted.
Deterministic vs. Inferred: The Trust Layer in Every Spec
Architects evaluating AI-based analysis tools ask a fair question: if the agent is reasoning rather than parsing, how do I know which parts of the output to trust?
CoreStory answers this with an explicit confidence layer built into every specification. Each finding carries a trust indicator based on how it was derived:
High confidence findings come from deterministic analysis — AST parsing of well-formed syntax, explicit function calls, defined API contracts, traced event schemas. These are facts extracted directly from the code.
Medium confidence findings come from pattern matching and symbolic execution — the evidence is strong and structural, but involves inference across paths. For example, a traced Kafka event schema where the producer and consumer agree on field names but the contract was never formally documented.
Low confidence findings come from LLM inference — intent extracted from function names, comments, architectural patterns, or naming conventions. This is where stale comments become a risk: if a comment was written three years ago and the code has since changed, the agent flags the discrepancy between structural evidence and commented intent rather than silently accepting the comment at face value.
The result is a specification that architects can work with in layers: use the high-confidence findings as the authoritative system map, use medium-confidence findings as strong hypotheses to verify, and use low-confidence findings as a targeted review list for subject matter experts — rather than requiring full manual review of everything.

Why Agents Beat Parsers
The traditional approach to multi-language support follows a predictable pattern: build a Java parser, ship Java support. Build a Python parser, ship Python support. Build a Go parser, ship Go support. Each new language represents six to twelve months of R&D. Cross-language tracing requires manual integration. And framework-specific patterns and version-level differences routinely break parsers built for a prior version or dialect.
CoreStory's polymorphic agent architecture obviates this model entirely.
When an agent encounters code, it identifies the language and selects the best tool for the specific context. It handles framework idioms and version differences through reasoning rather than hardcoded rules. New languages are added through training, not by rebuilding infrastructure. And cross-language tracing isn't a bolt-on feature — it's native behavior from the first analysis.
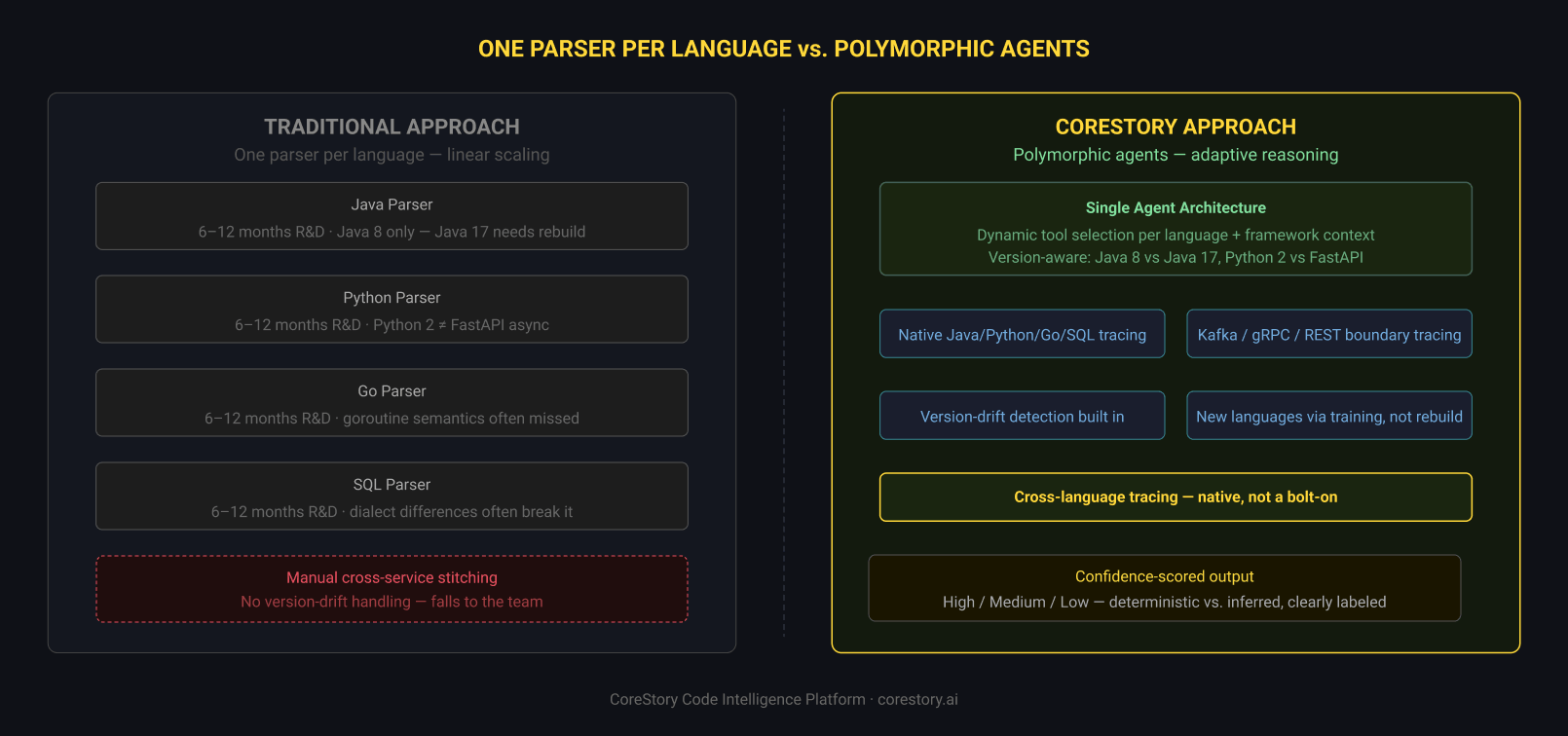
The difference isn't incremental. Agents compose tools the way experienced engineers do — selecting the right analysis technique for the specific code in front of them, switching approaches mid-analysis when the context demands it, and synthesizing findings across language and service boundaries into coherent, trust-layered specifications.
The Polymorphic Agent Decision Loop
Every analysis follows a five-stage decision loop. The best way to understand it is to follow a concrete example across a real multi-language production system:
- the agent encounters a code artifact — `order-processor/src/main/java/OrderService.java`.
- it identifies the language as Java 17 with Spring Boot, using REST endpoints and a PostgreSQL connection pool.
- it selects the tools best suited to this artifact: an AST parser combined with a Spring annotation analyzer and a SQL schema linker.
- it analyzes the code — discovering an outbound HTTP call to a Python-based pricing service, and an event published to a Kafka topic consumed by a Go notification service. During analysis of the Python service, the agent also encounters an undocumented field in the JSON payload — a "shadow" field present in the response but absent from the formal API definition. Rather than ignoring it, the agent flags it as a medium-confidence finding: the field exists in observed responses, its name suggests a discount application, but its exact semantics require verification with the team that owns the pricing service.
- it synthesizes findings across all three services, the PostgreSQL schema, and the Kafka event contract — tagging each element with its confidence level and surfacing the shadow field as an explicit annotation in the output spec.
The result is a unified specification that captures how order processing actually works — including the parts that aren't formally documented — without any manual work from your team.
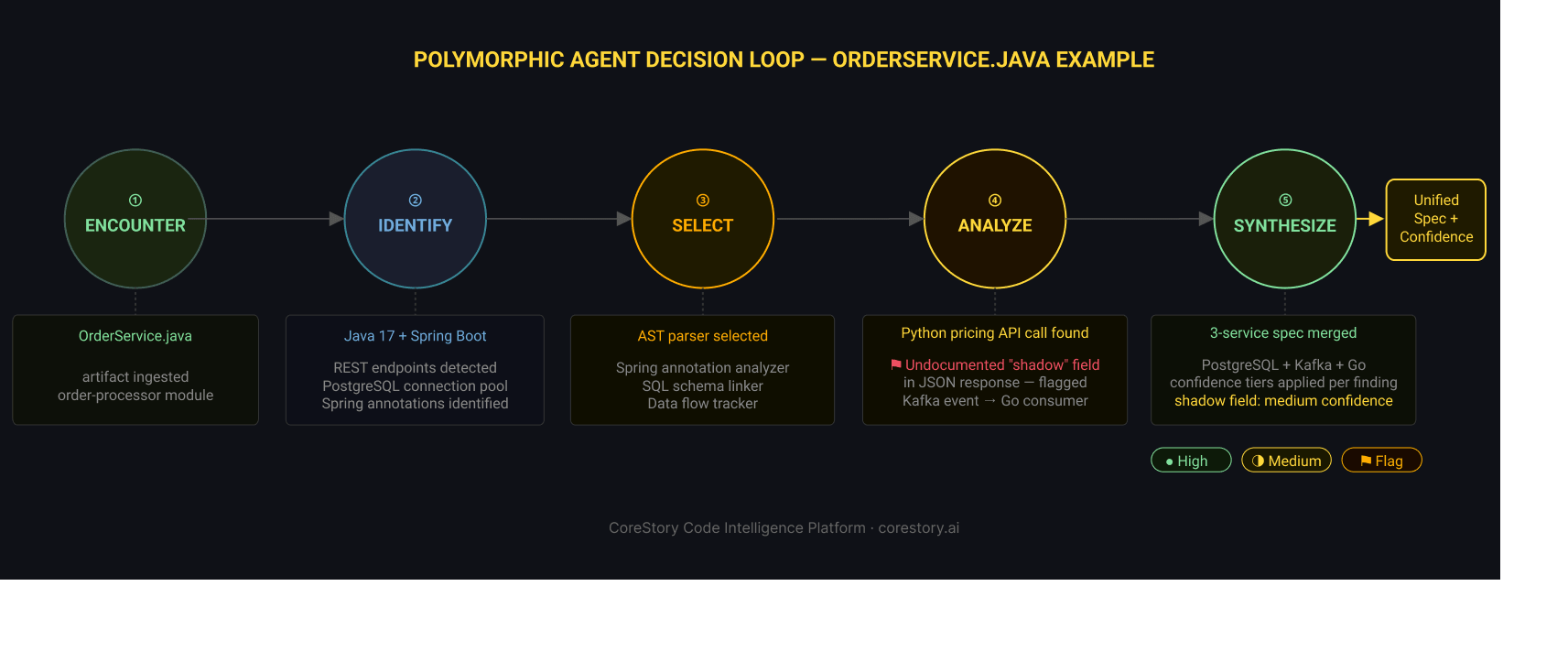
No manual stitching. No integration-point blind spots. One coherent, trust-layered understanding of a complex polyglot production system.
Handling What the Code Doesn't Say: Third-Party APIs and External Dependencies
One of the most common gaps in cross-language analysis is the external service boundary: a REST call to Stripe, a Twilio webhook, a Salesforce integration. The source code for these services isn't available but the interaction is often critical to the business rules you're trying to understand.
Polymorphic agents handle external dependencies through a combination of schema inference and contract analysis. When the agent encounters an outbound HTTP call to an external API, it analyzes the request and response structures observed in the code — headers, payload shapes, error handling paths — and cross-references them against known API schemas where available (OpenAPI specs, published documentation, SDK types). For well-documented APIs like Stripe or Twilio, this produces high-confidence external dependency nodes in the specification. For internal APIs with no formal documentation, the agent uses structural inference to map what the code expects and flags gaps in the contract as explicit low-confidence findings.
The result is a specification that includes external dependencies as first-class nodes — not invisible black boxes at the edge of the system map — with a clear indication of how much of each dependency's behavior was formally confirmed versus inferred.
The Polymorphic Tool Palette
The power of polymorphic agents lies in the breadth and composability of their analysis toolkit. Unlike tools that hardcode a single parser per language, CoreStory agents have access to a palette of analysis techniques. For each code artifact, the agent evaluates which combination will yield the deepest understanding, then orchestrates them.

The agent selects the combination that fits the specific code it's analyzing — the same way an experienced systems engineer approaches an unfamiliar codebase.
The Compounding Advantage
Here's what makes the polymorphic agent architecture a structural advantage rather than a feature: every language and framework CoreStory learns makes every other language more accurate.
Cross-language patterns create transfer learning effects that single-language tools can never achieve. When the system learns how Java services interact with PostgreSQL, that understanding improves its analysis of Python services that use the same database schema. When it maps Kafka event schemas, that knowledge enriches its understanding of every service — regardless of language — that participates in those event flows. When it understands how a REST API contract is defined in one service, it can correctly interpret how consumers in other languages interact with it.
Parsers scale linearly — each new language requires building, testing, and maintaining a new parser from scratch. Adding Go support to a parser-based tool means an entirely new engineering effort, independent of everything that came before.
Polymorphic agents scale differently. CoreStory's agents learn new languages through training examples and by leveraging existing cross-language reasoning patterns. Adding support for a new language or framework takes weeks, not quarters. And the cross-language context fusion native to the architecture means the system sees the whole system — not just the components written in one language.
A parser sees one language. An agent sees the system.
Keeping the Intelligence Current: Versioning and Drift
A reasonable CIO question is: what happens when the system changes? Does the specification go stale? Does adding a new Python framework version require re-training?
CoreStory's living intelligence model is designed for continuous operation, not point-in-time snapshots. When a new version of a service is deployed, the agent re-analyzes the affected components and propagates changes through the cross-language dependency graph. If a Python service migrates from Django to FastAPI, the agent detects the framework change, updates its pattern-matching strategy for that service, and flags any downstream consumers whose integration assumptions may have changed.
Specification drift (the accumulated gap between what a specification says and what the system actually does) is addressed through a combination of continuous re-ingestion and conflict detection. When the agent encounters code that contradicts an existing spec element (a renamed field, a changed API contract, a removed endpoint), it surfaces the conflict explicitly rather than silently overwriting the prior finding. This means the specification is a living document that reflects the current system, with explicit audit trails for what changed and when.
For new framework versions, the agent doesn't require a "re-training phase" in the sense of a manual intervention. Framework pattern libraries are updated through CoreStory's training pipeline, and updated patterns are available to all agents automatically. An upgrade from Spring Boot 2 to Spring Boot 3 across a service is detected, the new annotation and configuration patterns are applied, and the affected spec elements are updated with their confidence levels re-evaluated based on the new evidence.
Stop Waiting for Your Tool to Add a Language
If your code intelligence tool only understands one language well, it only understands part of your system. The Python data pipelines, the Go APIs, the SQL stored procedures, the TypeScript frontends, the Bash automation scripts — each one that falls outside your tool's primary coverage becomes a blind spot.
Those blind spots don't stay hidden. They surface when a refactored service breaks a consumer written in a different language. They appear when business rule extraction misses logic that lives in a stored procedure rather than application code. They show up in modernization programs when the specification covers 60% of the system and the team has to reconstruct the rest manually.
CoreStory's polymorphic agent architecture was built from the ground up to handle the polyglot reality of large production systems. Not by building a separate parser for every language, but by building agents that reason about code the way experienced engineers do — adapting their approach based on the subject of their analysis, tracing across every integration boundary, distinguishing what is known from what is inferred, and producing unified specifications that give engineering teams a complete and trustworthy picture of how their system actually works.
Talk to an expert to see how polymorphic agents can analyze your full production system — every language, every framework, every cross-service dependency — and produce the confidence-scored specifications your team needs to move fast without breaking things.
FAQ
How many programming languages does CoreStory support?
CoreStory supports all major production languages, including Java, Python, Go, TypeScript/JavaScript, Ruby, C/C++, Rust, Scala, Kotlin, PHP, and more, as well as SQL dialects and proprietary DSLs. Because polymorphic agents learn through training rather than hardcoded parsers, new language and framework support can be added in weeks rather than the six to twelve months required by parser-based approaches.
What's the difference between a polymorphic agent and a traditional code parser?
A traditional parser is a tool built for one specific language. It follows rigid grammar rules and produces an abstract syntax tree. A polymorphic agent dynamically selects from multiple analysis techniques — of which AST parsing is one — as well as pattern matching, symbolic execution, LLM inference, and more based on the specific code it encounters. It also tracks which technique produced each finding, so the output specification distinguishes deterministic facts from probabilistic inferences.
How does CoreStory handle undocumented fields and "shadow" schemas in API contracts?
When the agent encounters an undocumented field in an API response — for instance a field present in observed payloads but absent from the formal contract — it doesn't ignore it. It flags the field as a medium-confidence finding, notes the discrepancy between the observed payload and the documented schema, and includes it as an explicit annotation in the output spec. This surfaces hidden integration dependencies that would otherwise only be discovered when something breaks.
How does CoreStory handle third-party APIs like Stripe or Twilio where source code isn't available?
External API interactions are analyzed through a combination of schema inference and contract cross-referencing. For well-documented APIs, the agent cross-references observed request/response structures against published OpenAPI specs and SDK types, producing high-confidence external dependency nodes. For undocumented or internal APIs, it uses structural inference to map what the code expects and flags gaps as explicit low-confidence findings. External dependencies appear as first-class nodes in the specification — not invisible boundaries at the edge of the system map.
How does confidence scoring work, and what do I do with low-confidence findings?
Every finding in a CoreStory spec carries a confidence indicator: high (derived from deterministic analysis like AST parsing or symbolic execution), medium (derived from a combination of deterministic analysis and inference), or low (derived purely from LLM inference on ambiguous constructs). Low-confidence findings are surfaced with annotations explaining what was inferred and what a human reviewer should verify. This structures the review process around findings that genuinely need expert judgment, rather than requiring full-spec review of every output.
How does CoreStory handle version differences across a single system (for example, some services on Java 8 and others on Java 17)?
Version awareness is built into the language-identification step. When the agent encounters a Java service, it identifies which version it targets based on syntax patterns, bytecode targets, and framework versions in use. Services running Java 8 and Java 17 are analyzed with version-appropriate strategies. If a Java 8 service calls a Java 17 service, the agent identifies the version boundary as an integration point and flags any API patterns that behave differently across versions.
Does adding a new framework version require re-training CoreStory?
No manual re-training is required. Framework pattern libraries are updated through CoreStory's training pipeline and distributed automatically. When a service upgrades from Spring Boot 2 to Spring Boot 3, the agent detects the changed annotation and configuration patterns, applies the updated analysis strategy, and re-evaluates confidence levels for affected spec elements. The specification updates continuously as the system changes — it's not a point-in-time snapshot.
Does my code have to leave my network during LLM inference?
CoreStory supports both cloud and on-tenant deployment. In an on-tenant deployment, all analysis — including LLM inference — runs within your tenant, and no code or metadata leaves your environment. In the cloud deployment, code is processed in dedicated per-customer infrastructure and is not shared across tenants. In either case, the deterministic components of analysis (AST parsing, symbolic execution, data flow tracing) never require external model calls — only the LLM inference component does, and that component's findings are clearly separated and labeled in the output.
Can CoreStory trace execution across multiple languages and services?
Yes. Cross-language context fusion is a native capability of the polymorphic agent architecture. When a Java service calls a Python microservice via REST and publishes events consumed by a Go worker, CoreStory traces the full execution and data flow, producing a unified specification that captures the complete business logic — regardless of how many languages or runtimes are involved.
Does CoreStory integrate with existing tools like GitHub Copilot or Sourcegraph?
Yes. CoreStory exposes an MCP interface which enables any MCP client (such as GitHub Copilot or Cursor or Claude Code) to request the detailed intelligence which it provides.





